내용인 즉, @TransactionalEventListener를 사용할 때 AFTER_COMMIT(the default),AFTER_ROLLBACK, orAFTER_COMPLETION 옵션을 사용하였다면 이전 트랜잭션 리소스는 살아있어 참여는 가능하나 변경내용에 대해 커밋은 할 수 없다는 내용입니다.
그럼 어떻게 해결할 수 있을까?
이전 트랜잭션에 참여하는 것이 아닌 현재 시점부터 새로운 트랜잭션을 할당하여 사용하면 되는 것입니다!
@Component
@RequiredArgsConstructor
public class PointHistoryHandler {
//
@TransactionalEventListener
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void on(ChargedPoint event) {
//
포인트_충전_내역_생성();
}
@TransactionalEventListener
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void on(UsedPoint event) {
//
포인트_사용_내역_생성();
}
}
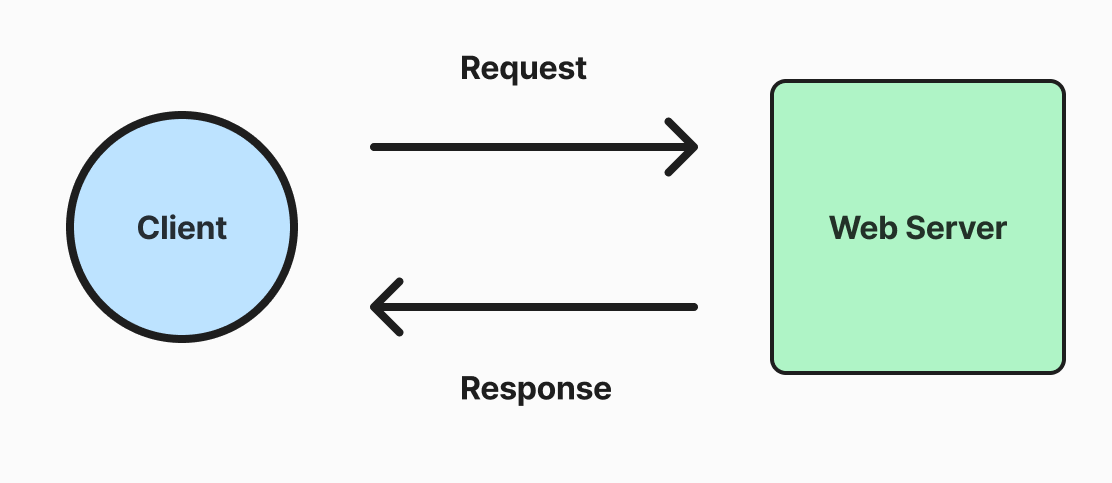
위와 같이 Transaction의 전파레벨을 Propagation.REQUIRES_NEW를 사용하면 새로 Transaction을 할당하여 정상적으로 변경사항을 Commit 또는 Rollback 할 수 있습니다.
기존 서버를 이벤트 없이 작업해 본 후, Spring Framework의 Spring-Event와 Kafka를 사용하여 이벤트 주도 설계를 도입하고자 합니다. 이를 통해 이벤트의 장점을 직접 체감하고, 클라우드 환경에서의 문제점을 해결하려고 합니다.
서비스 분석 및 EDA설계
우선 현재 묶여있는 Transaction범위에 대해 분석해 보고 이를 Event를 활용하여 분리한 TO-BE를 설계해 보도록 하겠습니다.
1. 콘서트시리즈과 좌석 생성 - 트랜잭션 분리 적합
콘서트 시리즈를 생성할경우 좌석이 1:N관계로 생성이 되도록 하였습니다.
이때 좌석이 생성되는 케이스까지 하나의 업무 단위라 판단하였고, 이를 트랜잭션으로 묶어 구현하였습니다.
하지만, 좌석이 생성될 때 실패할 일이 있을까?? 그리고 콘서트 시리즈와 콘서트 좌석을 한 트랜잭션으로 묶일 필요가 있을까라는 고민을 하였을 때 묶일 필요는 없다고 생각하였습니다.
그 이유는 우선 시리즈가 생성되고 좌석이 생성될 때 좌석은 하나의 시리즈에 종속적인 관계를 가지고 있습니다.
이는 좌석을 생성할 때 실패하는 케이스는 서버의 문제로 인해 생성 중에 서버가 죽는 경우 밖에 없다고 생각하였습니다.
하여 아래와 같이 설계를 해보았습니다.
시리즈와 좌석 생성
위와 같이 하나의 트랜잭션에 묶여있던 작업을 Kafka를 활용하여 책임을 분리하여 로직의 결합을 분리하였습니다.
이로써 콘서트 시리즈는 시리즈의 생성에 대한 책임을 가지게 되고, 좌석은 좌석 생성에 대한 책임을 가져 보다 응집도 높은 코드를 작성할 수 있습니다.
주의 콘서트 시리즈와 콘서트 좌석은 콘서트라는 메인 도메인의 서브 도메인으로써 Event를 사용하여 동기로 작동하기보다는 동기로 같이 처리하는 것이 나을 수도 있습니다. 이에 대해 같은 도메인 그룹안에 속해 있으면 어떻게 처리할지 고민을 해보는 것이 좋을 것 같습니다.
2. 포인트 충전 및 사용- 트랜잭션 분리적합
포인트를 충전하고 사용할 때마다 포인트는 History를 쌓고 있습니다.
이럴 때 기존 로직은 하나의 업무라 생각하여 트랜잭션을 묶어 구현을 하였습니다.
하지만, 포인트가 사용 및 충전 내역을 쌓는 거에 대한 책임을 가져야 하나?라는 생각이 들었습니다.
제가 생각할 때 포인트의 역할은 사용한다하면 잘 차감하고, 충전한다 하면 잘 충전하면 되는 것이지, 내역을 신경 쓸 필요는 없다 생각했습니다.
이러한 이유로 Point와 PointHistory를 Event를 활용하여 책임 분리를 진행하였습니다.
3. 좌석 임시 예약- 트랜잭션 분리부적합
콘서트 좌석을 임시예약하게 될경우 TemporaryReservation이란 데이터를 생성을 하고, ConcertSeat 좌석 테이블의 점유 상태를 변경을 해주는 작업을 수행해야 합니다.
이때 TemporaryReservation생성과 ConcertSeat 좌석 테이블의 점유 상태를 변경하는 작업을 분리해 보는 것을 생각해 볼 수 있습니다.
다만 주의해야 할 점이 ConcertSeat의 점유 상태를 보고 TemporaryReservation을 생성한다는 점입니다.
이는 임시 예약을 할 때 좌석 점유 상태는 매우 중요한 정보라는 것이고, 이는 트랜잭션 분리에 적합하지 않다고 생각합니다.
그로 인해 EDA로 설계하였을 때 아래 그림과 같은 문제가 발생할 수 있습니다.
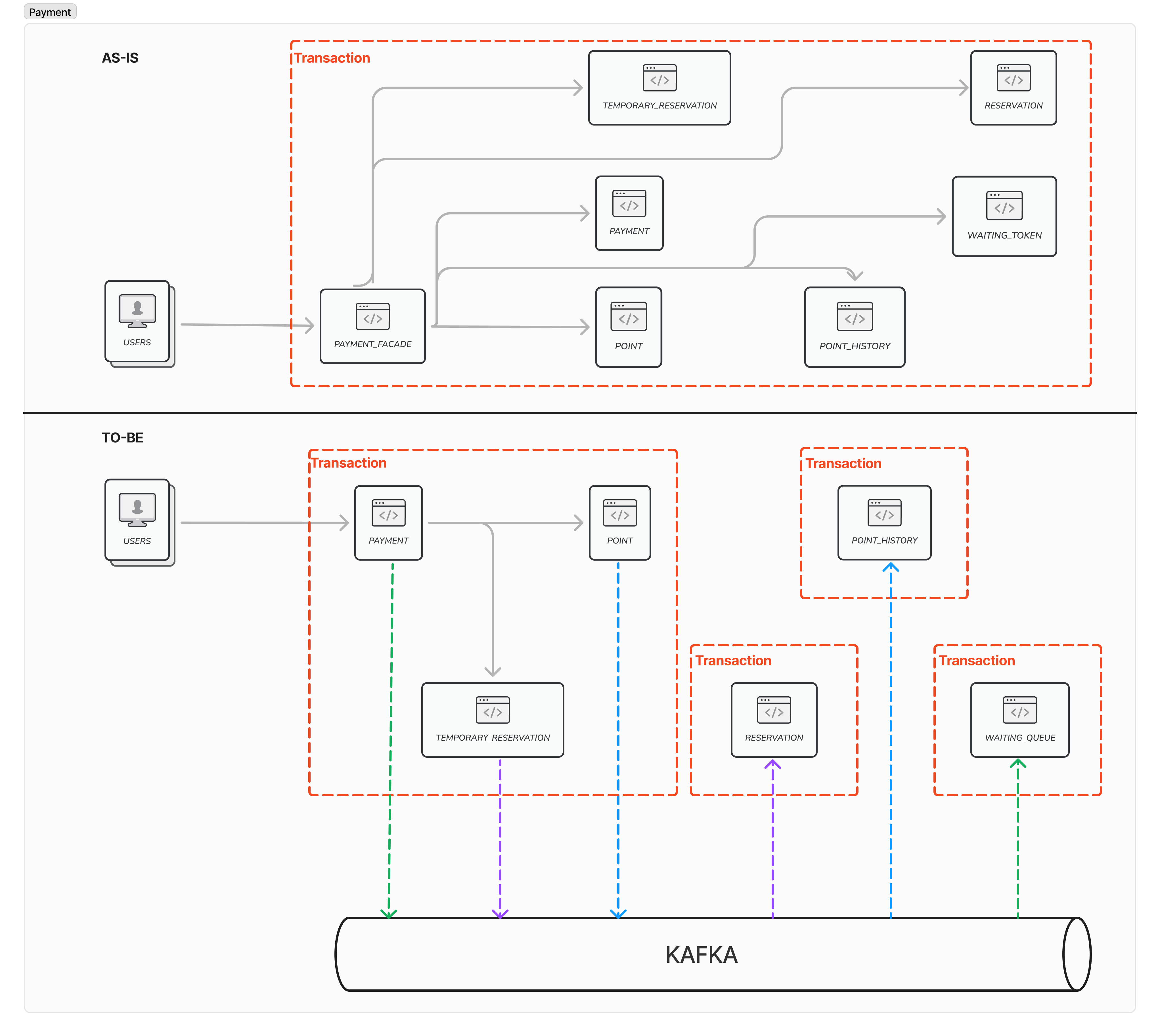
4. 결제- 트랜잭션 분리적합
결제의 경우 여러 작업들이 이뤄지는 만큼 기존 로직은 긴 트랜잭션을 유지하고 있었는데요.
이 긴 트랜잭션을 유지할 경우 DB Connect의 지속적인 연결을 통해 큰 성능 이슈가 있다 판단하였습니다.
또한 PaymentFacade에서 다른 도메인들을 호출하게 되면서 높은 결합도를 가진 코드가 생기게 되고, 이는 확장성에 영향을 준다고 판단하였습니다. 그리고, 앞에서 말한 긴 트랜잭션 또한 성능적 문제를 유발할 수 있다고 생각합니다.
다만 분리를 할 때 조심해야 하는 부분은 Point는 차감되어야 하는데, 이는 금전적인 부분이기 때문이기도 하고, 동기적으로 처리되어야 하며, 하나의 트랜잭션에 묶여있어야 좀 더 안정적인 서비스를 제공할 수 있다 판단하였습니다. 그리고, TemporaryReservation 또한 Paid라는 속성으로 인해 이벤트를 사용하여 트랜잭션을 분리하지 않는 것이 적합하다 판단하였습니다.
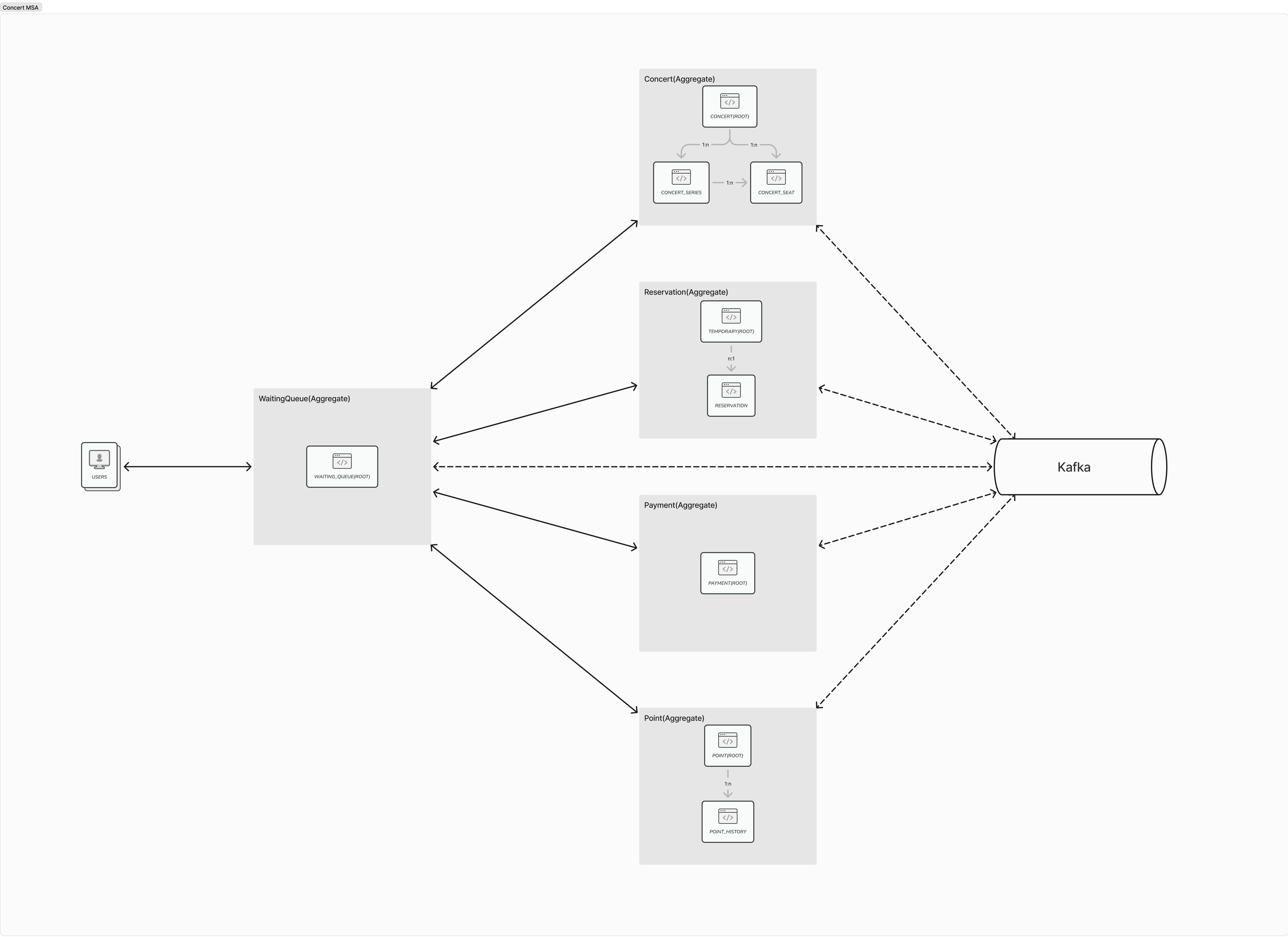
MSA로 분리한다면
MSA로 분리를 한다면 Domain별로 서비스를 분리해볼 수 있습니다.
도메인은 DDD에서 소개하는 Aggregate즉 Root Domain과 Sub Domain의 개념을 적용하였으며,
이를 통해 도메인별 연관관계를 생각하여 분리를 진행할 수 있습니다.
아래와 같이 책임에 따라 그리고, 기능에 따라 각 서비스는 WebClient를 활용한 동기처리, Event를 활용한 비동기 처리를 할 수 있습니다.
즉 서비스가 분리되어 트랜잭션이 분리되어있더라도, 동기처리를 통해 기존 방식과 동일한 기능을 활용할 수도 있습니다.
이번 콘서트 서비스를 분석하면서 저는 대기열을 관리하는 WaitingToken, 콘서트를 관리하는 Concert, 결제를 관리하는 Payment, 포인트를 관리하는 Point, 예약을 관리하는 Reservation으로 분리하여 관리하는 것으로 구상을 해 보았습니다.
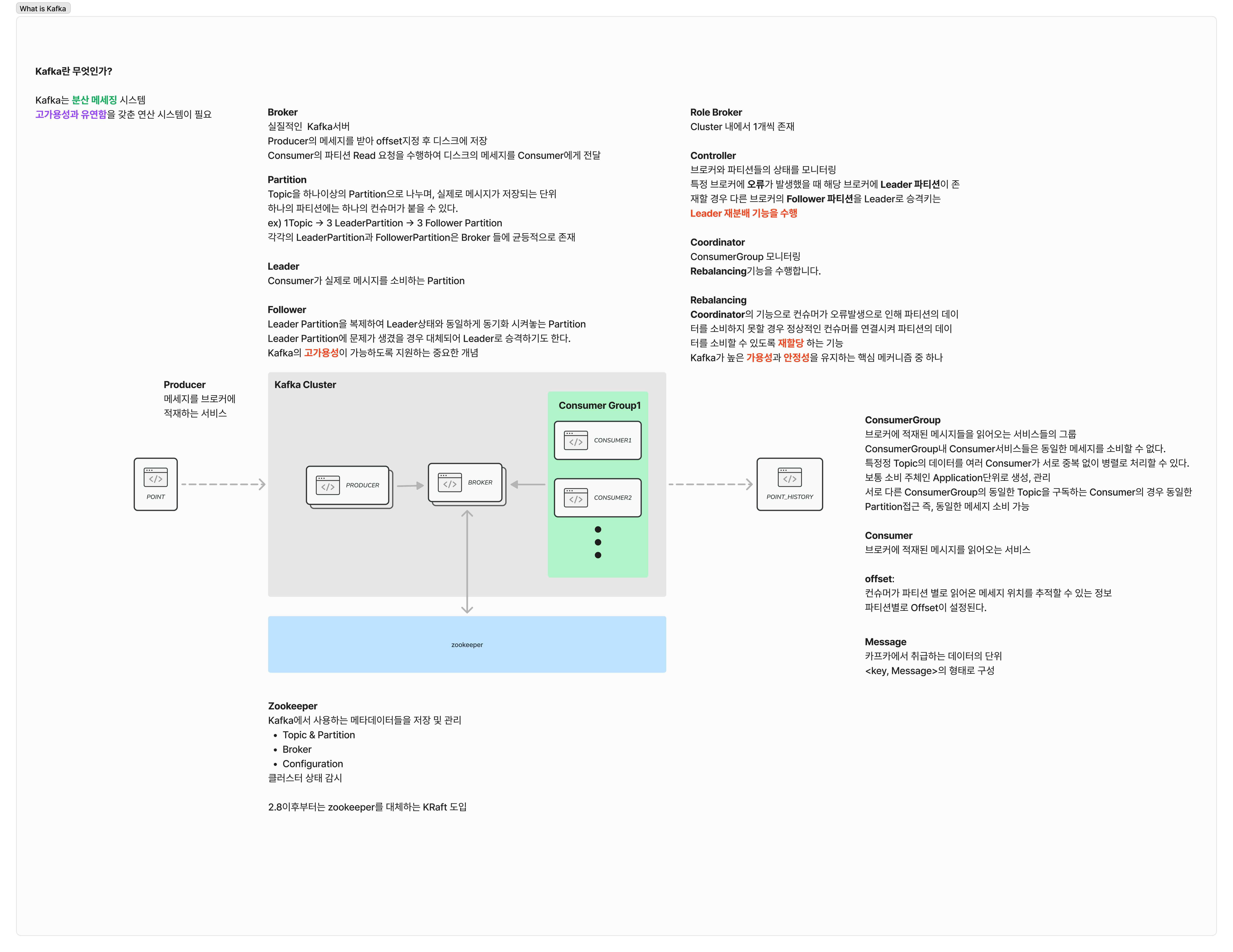
Kafka를 사용할 경우
Kafka는 이벤트 스트리밍 및 관리를 위한 강력한 도구로, 트랜잭션 내에서 오류가 발생하면 이벤트를 재시도할 수 있습니다. 이를 통해 시스템의 신뢰성과 가용성을 높일 수 있습니다.
EDA를 적용함에 있어 개인적인 생각
EDA를 적용하려면 철저한 설계가 필수적입니다. 트랜잭션을 완전히 분리하고, 데이터의 원자성을 보장할 작업과 비동기로 처리해도 무방한 작업을 명확히 구분해야 합니다.
SAGA 패턴, InBox/OutBox 패턴 등을 활용하여 보상 트랜잭션을 설계하는 것도 중요합니다. 다만, 트랜잭션을 분리한 만큼 보상 트랜잭션이 필요한가? 에 대한 의문은 필수적으로 가져야 한다 생각합니다.
무분별한 SAGA패턴, InBox/OutBox 패턴 등을 적용할 시 시스템 복잡도가 높아질 수 있으며, 만약 보상 트랜잭션의 순환이 이루어진다면 이는 매우 큰 오류로 서비스에 적용할 수 있습니다.
올바른 이벤트 설계 를 하게된다면 도메인간 결합도를 분리하여 응집도가 높고 결합도가 낮은 코드를 작성할 수 있으며, 이는 시스템의 확장성과 유지보수성을 높일 수 있습니다.