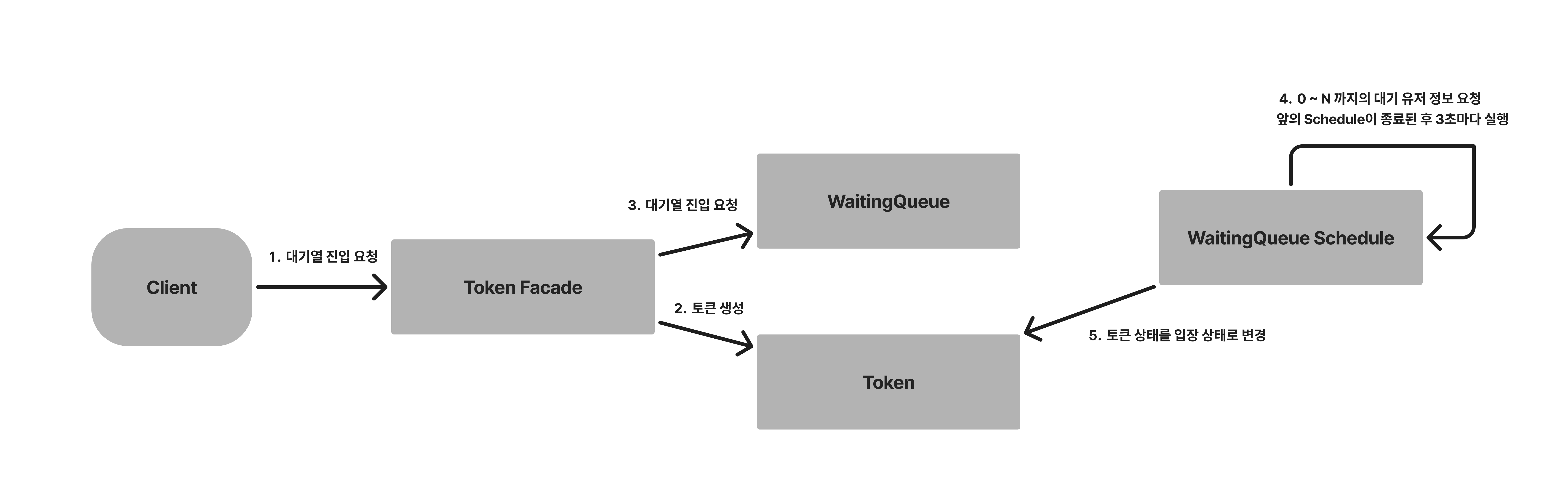
Rdb 대기열
대기열 진입
User A가 대기열 입장을 요청한다.
토큰을 Redy상태로 생성하고, 해당 토큰으로 대기열에 입장한다.
에러상황: 대기열에 이미 A의 정보가 존재할 경우 TOKEN_ALREADY_EXIST(409)를 발행한다.
순위 조회
User A가 대기열 순위를 조회 요청한다.
WaitingQueue를 Sort를 하여 본인의 순번이 몇 번 째인지 확인한다.
에러 상황: 대기열에 A의 정보가 없을 경우 WAITING_QUEUE_NOT_FOUND(401)를 발행한다.
서버 입장 토큰 생성 ( Schedule )
서버는 현재 생성된 토큰 수를 조회한다.
서버는 입장가능한 토큰 수와 현재 생성된 토큰 수를 비교하여 추가 입장 가능할 경우 WaitingQueue의 입장 가능한 토큰들의 아이디를 요청한다.
입장하는 토큰 아이디들로 토큰 상태를 입장 가능으로 변경한다.
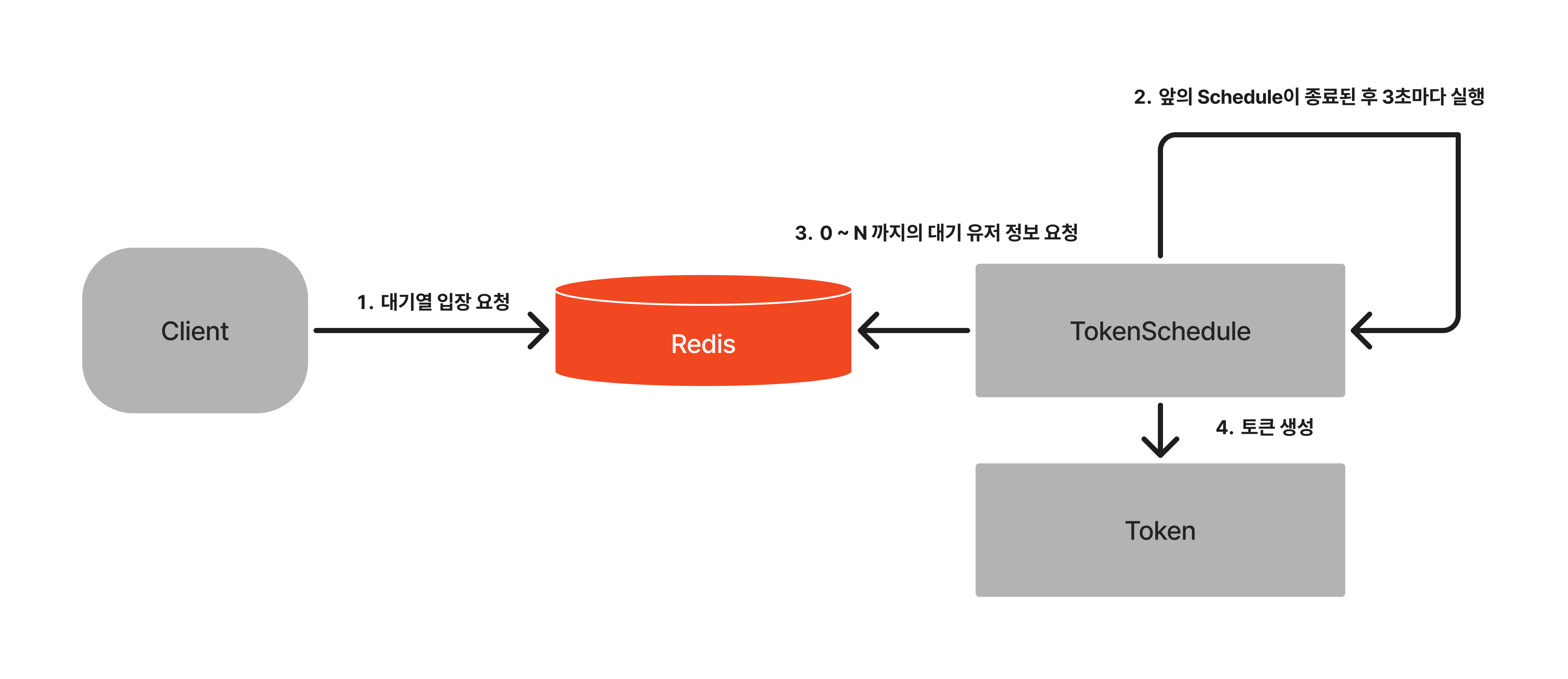
리펙토링 Redis 대기열
대기열 진입
User A가 대기열 입장을 요청한다.
Redis에서는 A의 정보( Value )와 요청 시간( Score )을 저장한다.
에러상황: 대기열에 이미 A의 정보가 존재할경우 WAITING_QUEUE_ALREADY_EXIST(409)를 발행한다.
순위 조회
User A가 대기열 순위를 조회 요청한다.
rank() 메소드를 활용하여 현재 A의 대기열 순위를 반환한다.
에러 상황: 대기열에 A의 정보가 없을 경우 WAITING_QUEUE_NOT_FOUND(401)를 발행한다.
서버 입장 토큰 생성 ( Schedule )
서버는 현재 생성된 토큰 수를 조회한다.
서버는 입장가능한 토큰 수와 현재 생성된 토큰 수를 비교하여 추가 입장 가능할 경우 Redis에 요청한다.
Redis는 range()를 통해 입장 가능한 유저 정보를 조회 후 추가 가능한 수만큼 정보를 서버로 반환한다.
서버는 Redis에게 제공받은 유저 정보로 Token을 생성한다.
Redis로 리펙토링 한 이유
Rdb를 이용해서 구현을 먼저 하였는데, 필요한 정보들이 많다 생각하여 Repository에게 많은 케이스의 조회 메서드를 요청하였고, 이는 비즈니스 로직을 복잡하게 구현하게 되면서 발생한 상황이었습니다.
코드로 비교를 해보겠습니다.
public interface WaitingQueueRepository {
Long save(WaitingQueue waitingQueue);
void saveAll(List<WaitingQueue> waitingQueues);
WaitingQueue findByTokenId(String tokenId);
WaitingQueue findPrevQueue(WaitingQueueStatus status);
List<WaitingQueue> findAllWithExpired(long expiredAt);
List<WaitingQueue> findAllByStatusAndOffsetLimit(WaitingQueueStatus status, int limit);
List<WaitingQueue> findAllByTokenIds(List<String> tokenIds);
Long countByStatus(WaitingQueueStatus status);
}public interface WaitingQueueRepository {
boolean save(WaitingQueue waitingQueue);
Long findWaitingQueueCount(WaitingQueue.WaitingQueueKey key);
List<WaitingQueue.WaitingQueueKey> findWaitingQueuesByJoinCount(Long joinCount);
boolean existWaitingQueue (WaitingQueue.WaitingQueueKey key);
void deleteWaitingQueues(List<WaitingQueue.WaitingQueueKey> waitingQueueKeys);
}
첫 번째 코드가 Rdb로 작성하였을 때, 그리고 두 번째 코드가 Redis를 사용하여 리펙토링을 진행한 코드입니다.
우선 딱 보기만 하더라도 크게 필요로 하는 메서드 양이 준 것이 보이고, 메서드의 용도들을 보면 용도가 명확한 메서드들만 제공하고 있습니다.
이렇듯 첫 번째로 구현 코드의 단순화가 가장 큰 장점이었습니다.
두 번째로 성능입니다.
Redis의 ZSet의 경우 Sorted set 자료구조를 활용함으로써 Rank 등 다양한 기능들을 빠르게 제공을 해주고 있었고, 이를 데이터를 조회하여 이전 대기열 데이터와 비교하는 비즈니스 로직등을 제거할 수 있게 되면서 필요 없던 기능들을 제거하고, 명확하게 필요한 기능들만 사용할 수 있었습니다.
성능 차이


위 두 성능 측정 데이터를 보시면 대기시간 및 반복 요청시간들을 보면 시간차이가 꽤 나는 것을 확인해 보실 수 있습니다.
또한 동일하게 1분 동안 100명의 유저가 대기열 진입 요청을 시도한 시도인데 Redis구현한 대기열에 시도한 것을 보면 Rdb로 구현한 대기열에 시도한 횟수보다 100개가 더 많은 것을 볼 수 있습니다.
이는 서버에서 Redis로 구현한 대기열이 좀 더 요청을 좀더 빨리 처리하여 Rdb로 구현한 대기열보다 더 많은 트래픽을 감당한 것으로 성능은 Redis로 구현한 대기열이 더욱 좋은 것으로 보입니다.
'Server' 카테고리의 다른 글
| [Event] @TransactionalEventListener 데이터가 저장 안 돼요... (0) | 2024.08.11 |
|---|---|
| [EDA] 기존 서비스를 분석하고 Event를 활용하여 Transaction범위 분리 작업 (0) | 2024.08.07 |
| [ Caching ] 캐싱 적용 API분석 및 K6를 사용한 성능 테스트 결과 (0) | 2024.08.01 |
| Lock( 비관적, 낙관적, 분산 )적용 상황 분석 및 테스트 결과 (2) | 2024.07.26 |
| [Kafka] 설치하기 (0) | 2024.06.07 |