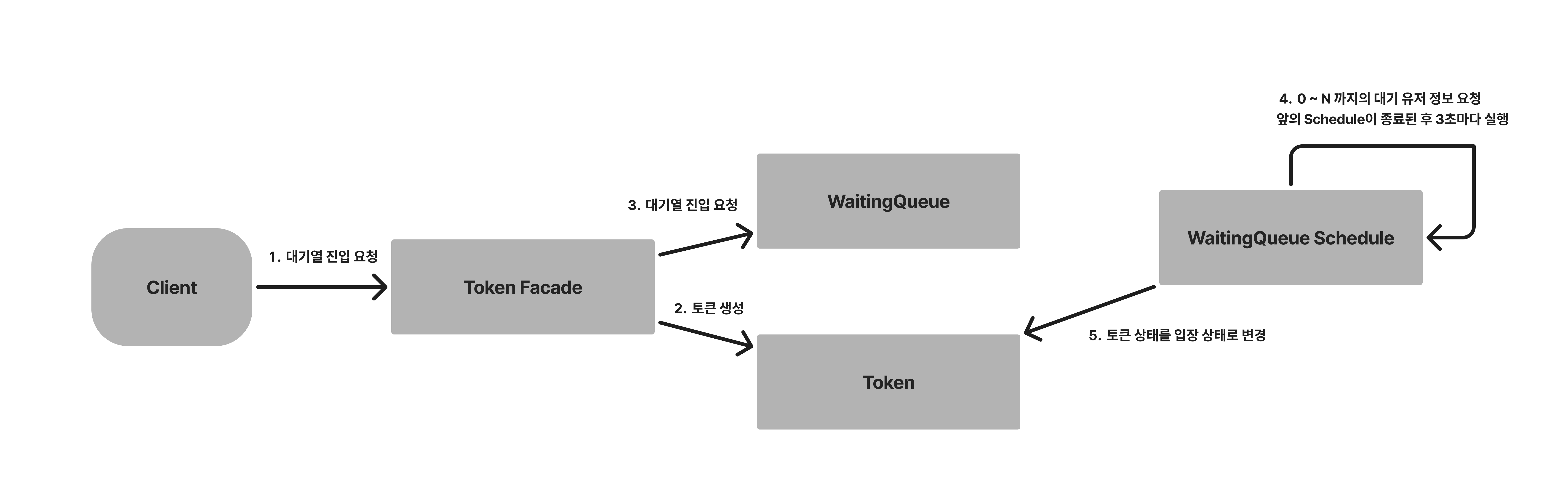
User A가 대기열 입장을 요청한다. 토큰을 Redy상태로 생성하고, 해당 토큰으로 대기열에 입장한다.
에러상황: 대기열에 이미 A의 정보가 존재할 경우 TOKEN_ALREADY_EXIST(409)를 발행한다.
순위 조회
User A가 대기열 순위를 조회 요청한다.
WaitingQueue를 Sort를 하여 본인의 순번이 몇 번 째인지 확인한다.
에러 상황: 대기열에 A의 정보가 없을 경우 WAITING_QUEUE_NOT_FOUND(401)를 발행한다.
서버 입장 토큰 생성 ( Schedule )
서버는 현재 생성된 토큰 수를 조회한다. 서버는 입장가능한 토큰 수와 현재 생성된 토큰 수를 비교하여 추가 입장 가능할 경우 WaitingQueue의 입장 가능한 토큰들의 아이디를 요청한다. 입장하는 토큰 아이디들로 토큰 상태를 입장 가능으로 변경한다.
리펙토링 Redis 대기열
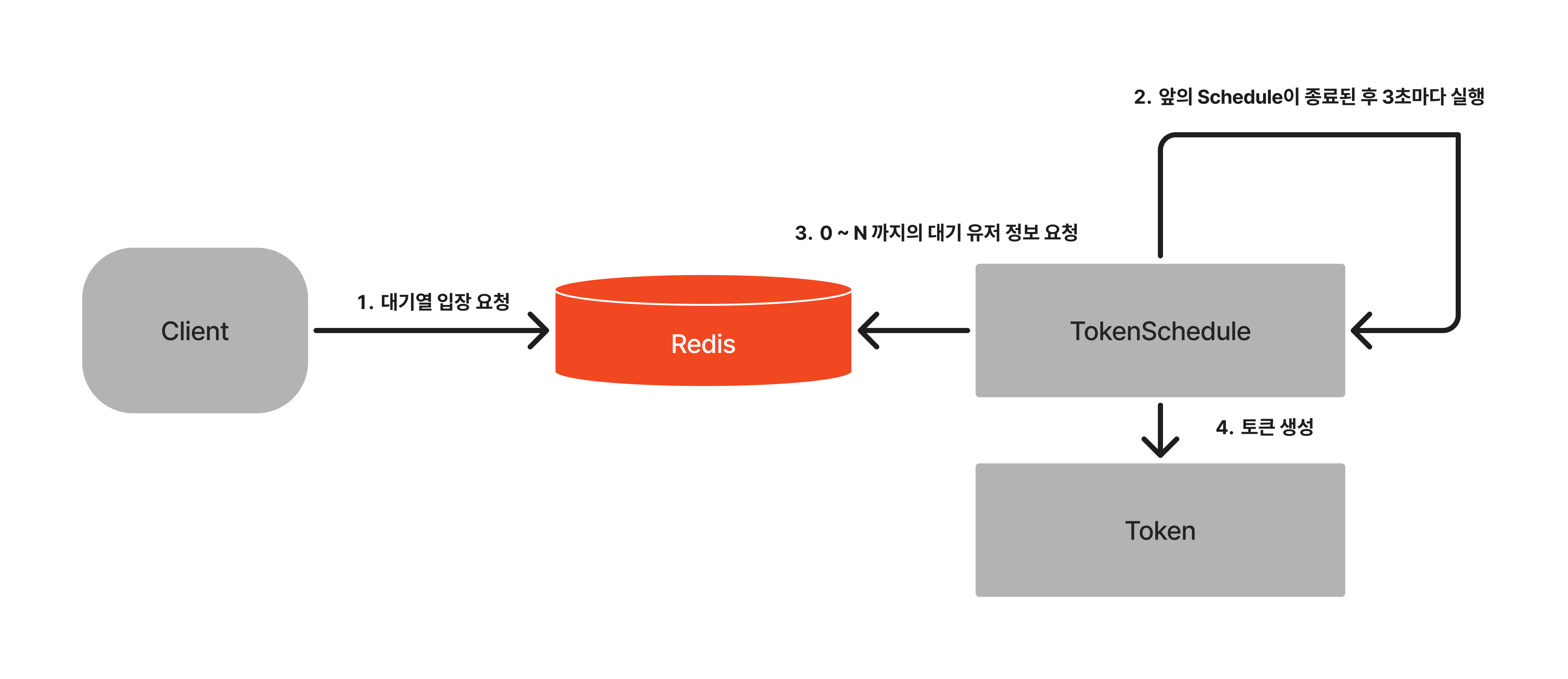
대기열 진입
User A가 대기열 입장을 요청한다. Redis에서는 A의 정보( Value )와 요청 시간( Score )을 저장한다.
에러상황: 대기열에 이미 A의 정보가 존재할경우 WAITING_QUEUE_ALREADY_EXIST(409)를 발행한다.
순위 조회
User A가 대기열 순위를 조회 요청한다. rank() 메소드를 활용하여 현재 A의 대기열 순위를 반환한다.
에러 상황: 대기열에 A의 정보가 없을 경우 WAITING_QUEUE_NOT_FOUND(401)를 발행한다.
서버 입장 토큰 생성 ( Schedule )
서버는 현재 생성된 토큰 수를 조회한다. 서버는 입장가능한 토큰 수와 현재 생성된 토큰 수를 비교하여 추가 입장 가능할 경우 Redis에 요청한다. Redis는 range()를 통해 입장 가능한 유저 정보를 조회 후 추가 가능한 수만큼 정보를 서버로 반환한다. 서버는 Redis에게 제공받은 유저 정보로 Token을 생성한다.
Redis로 리펙토링 한 이유
Rdb를 이용해서 구현을 먼저 하였는데, 필요한 정보들이 많다 생각하여 Repository에게 많은 케이스의 조회 메서드를 요청하였고, 이는 비즈니스 로직을 복잡하게 구현하게 되면서 발생한 상황이었습니다.
코드로 비교를 해보겠습니다.
public interface WaitingQueueRepository {
Long save(WaitingQueue waitingQueue);
void saveAll(List<WaitingQueue> waitingQueues);
WaitingQueue findByTokenId(String tokenId);
WaitingQueue findPrevQueue(WaitingQueueStatus status);
List<WaitingQueue> findAllWithExpired(long expiredAt);
List<WaitingQueue> findAllByStatusAndOffsetLimit(WaitingQueueStatus status, int limit);
List<WaitingQueue> findAllByTokenIds(List<String> tokenIds);
Long countByStatus(WaitingQueueStatus status);
}
첫 번째 코드가 Rdb로 작성하였을 때, 그리고 두 번째 코드가 Redis를 사용하여 리펙토링을 진행한 코드입니다.
우선 딱 보기만 하더라도 크게 필요로 하는 메서드 양이 준 것이 보이고, 메서드의 용도들을 보면 용도가 명확한 메서드들만 제공하고 있습니다.
이렇듯 첫 번째로 구현 코드의 단순화가 가장 큰 장점이었습니다.
두 번째로 성능입니다.
Redis의 ZSet의 경우 Sorted set 자료구조를 활용함으로써 Rank 등 다양한 기능들을 빠르게 제공을 해주고 있었고, 이를 데이터를 조회하여 이전 대기열 데이터와 비교하는 비즈니스 로직등을 제거할 수 있게 되면서 필요 없던 기능들을 제거하고, 명확하게 필요한 기능들만 사용할 수 있었습니다.
성능 차이
Rdb로 구현한 대기열Redis로 구현한 대기열
위 두 성능 측정 데이터를 보시면 대기시간 및 반복 요청시간들을 보면 시간차이가 꽤 나는 것을 확인해 보실 수 있습니다.
또한 동일하게 1분 동안 100명의 유저가 대기열 진입 요청을 시도한 시도인데 Redis구현한 대기열에 시도한 것을 보면 Rdb로 구현한 대기열에 시도한 횟수보다 100개가 더 많은 것을 볼 수 있습니다.
이는 서버에서 Redis로 구현한 대기열이 좀 더 요청을 좀더 빨리 처리하여 Rdb로 구현한 대기열보다 더 많은 트래픽을 감당한 것으로 성능은 Redis로 구현한 대기열이 더욱 좋은 것으로 보입니다.
Caching이 무엇이고, 어떤 상황에 도입하는 것이 적합한지 그리고 마지막으로 적용 안 했을 때와 적용했을 때의 성능 차이가 얼마나 차이 나는지 검증해 보겠습니다.
Caching이란?
캐싱은 자주 접근하는 데이터를 캐시라는 고속 데이터 저장소에 저장하고 접근하여 이후 동일한 데이터를 요청할 시 고속 데이터 저장소에 접근하여 데이터를 사용하는 방법입니다.
이는 많은 리소스를 요구하는 데이터베이스 커넥트 비용을 줄여주게 되어 서버와 데이터베이스에 가해지는 부하를 분산할 수 있다는 장점이 있습니다.
그럼 단점은 무엇일까??
우선 데이터의 일관성에 문제가 발생할 수 있습니다.
캐싱이란 것은 데이터베이스에 존재하는 데이터를 가져와 메모리에 올려두고 다음 요청 시 메모리에 존재한다면 메모리에서 해당 데이터를 가져오는 방식을 사용하게 되는데, 이때 데이터베이스에 존재하는 원본 데이터가 추가, 수정, 삭제와 같은 작업이 이루어진다면, 메모리상에 존재하는 데이터와 데이터 일관성이 깨져 유저에게 저퀄리티 즉 상한 데이터를 제공하게 됩니다.
이는 서비스 신뢰도의 저하를 야기할 수 있으며, 데이터의 일관적이지 않은 상황으로 인해 큰 오류로 이어질 수 있는 위험한 상황이라 생각합니다.
또한, 캐싱을 한다는 것 자체가 메모리에 데이터를 띄워놓고 사용한다는 의미인데, 이는 또 다른 메모리 자원을 사용하는 것이므로 무분별한 캐시 사용보다는 적합도를 추측 및 성능 검증을 통해 조심하게 사용해야 한다 생각합니다.
그리고, 요즘 많이 사용하는 k8s를 적용할 경우 하나의 서버를 여러 개의 Pod로 인스턴스를 할당해 운영할 수 있습니다.
이때, Local Cache를 사용하게 된다면 Pod들마다 저장하는 Local Cache의 정합성이 깨질 수 있습니다.
이렇듯 본인의 서버가 단일/복수의 인스턴스로 실행할 것인지, 수정이 많이 이뤄지는 데이터인지 등에 따라 제대로 사용한다면 유의미한 성능향상을 이뤄낼 수 있습니다.
Concert서비스 어디에 적용하는 것이 적절할까?
위에서 보았듯 여러 상황을 고려하며 어디에 적용할지 분석해 보겠습니다.
Local Caching VS Global Caching
Spring을 사용하시는 분이라면 Spring에서 제공해 주는 @Cacheable 어노테이션을 사용하여 캐싱을 적용해 보셨을 것입니다.
Spring에서 제공하는 캐싱은 AOP기반으로 작동하며, 캐시 데이터는 ConcurrentHashMap 기반의 저장소를 제공하고 있습니다. 이는 무엇인가? ConcurrentHashMap은 Multi-Thread에서 사용가능하며, ThreadSafe 합니다. 이 말은 하나의 서버 인스턴스 내에 생성된 스레드들은 해당 캐시를 공유하고 있다는 의미입니다.
물론 Spring에서 제공하는 어노테이션을 활용한다면 간단하게 캐싱을 적용할 수 있지만 이는 멀티 인스턴스 구조 즉 분산환경에서 Local Cache를 적용하는 것이 적합한가?? 는 다시 한번 고민해 볼 필요가 있습니다.
Global Cache는 이러한 관점에서 본다면 확실한 장점이 존재합니다.
외부 Storage를 사용하여 서버 인스턴스들이 해당 Storage를 접근함으로써 모든 인스턴스들은 캐시를 공유함으로써 데이터 정합성이 보장되게 됩니다.
또한 Local Cache의 경우 저장 하는 메모리가 JVM상에 존재하는 메모리를 활용하여 캐시가 많아질수록 서버 성능에 영향을 미칠 수 있는 반면 Global Cache는 외부에 존재함으로 서버 성능에 악영향은 없을 것으로 판단됩니다.
다만 따로 메모리 케쉬 서버를 사용하는 만큼 추가적인 비용과 캐싱 구현이 Local Caching보다 복잡한 점을 염두하여 어떤 캐시를 사용할 것인지 선택하면 될 거 같습니다.
Caching 적용 API 적합도 분석
캐싱은 보통 조회가 자주 일어나는 부분, 연산이 이뤄진 데이터를 자주 조회하는 경우에 사용한다고 생각합니다.
그럼 콘서트 서비스를 기준으로 한번 적합도를 분석해 보도록 하겠습니다.
1. 콘서트
콘서트는 콘서트 정보를 관리하는 Concert, 콘서트의 실질적인 open일 등 자세한 정보를 관리하는 ConcertSeries, 좌석정보를 관리하는 ConcertSeat 이렇게 3개로 분리하여 관리 중입니다.
위 3가지의 항목에 대해 적합도를 분석하겠습니다.
Concert 적합도:상 판단 근거: CRUD에 의거하여 생각해 보자면, 콘서트는 CUD의 빈도가 크지 않을 것이라 판단되는 도메인입니다. 그 이유는 현재 CR API만을 제공하고 있고, 콘서트의 Title 등만을 관리할 뿐 실질적인 데이터는 ConcertSeries에서 관리하고 있기 때문입니다.
하지만 유저가 가장 많이 접근하는 API일 것을 생각해 보면 Cache를 적용하여 조회성능을 향상하고, 생성될 때 Cache를 재업로드 하는 방식은 매우 적절할 것으로 판단됩니다.
그러므로 Caching을 적용하고 콘서트 데이터를 생성할 때 Cache정보를 최신정보로 갱신하도록 하겠습니다.
ConcertSeries 적합도: 중 판단 근거: ConcertSeries는 콘서트의 상세 정보, 신청 기간 등을 관리합니다. 이는 CRUD 중 CU의 기능을 활용 중이며, 이는 자주 Update 된다면 Cache를 거는 것이 오히려 악조건이 될 수 있습니다.
하지만, ConcertSeries의 경우 그렇게 자주 수정이 이루어질 것 같지 않아 Caching을 적용하되, 생성과 수정 시 갱신하는 방향으로 적용하겠습니다.
ConcertSeat 적합도: 하 판단 근거: 콘서트 좌석의 정보를 관리하고 있는 도메인입니다. 좌석의 예약 여부를 상태로 관리하고 있으며, 이 상태 데이터로 인해 Caching을 ConcertSeat에는 적용하지 않겠습니다.
2. 포인트
Point 적합도: 하 판단근거: 포인트는 자주 변경되는 사항이 아닐 수 있지만. 금전적인 부분을 다루는 만큼 데이터의 일관성이 무엇보다 중요하다 생각합니다. 이로 인해 Point에는 Caching을 적용하지 않겠습니다.
3. 임시예약
TemporaryReservation 적합도: 하 판단근거: 임시예약 API입니다. 해당 도메인의 경우 5분 안에 결제가 되지 않는다면 취소되는 요구조건으로 인해 주기적으로 많은 Update가 발생할 수 있습니다. 또한 결제가 될 경우에도 상태가 변경되므로 Cache를 적용하는 것은 적합하지 않다 생각하였습니다.
4. 예약
Reservation 적합도: 상 판단근거: 예약 데이터의 경우 생성하고 나면 환불하지 않는 한 수정 및 삭제가 이루어지지 않는다고 생각하여 구현하였습니다. 즉 캐시 갱신이 이뤄지는 시점은 생성과 삭제 부분만 있다고 생각합니다. 하여 캐싱이 적용되기 합당하다 생각합니다.
성능테스트
성능 테스트 도구: K6
vus: 100
duration: 60s
콘서트 조회
Concert 1000건의 데이터를 가지고 테스트를 진행하였습니다.
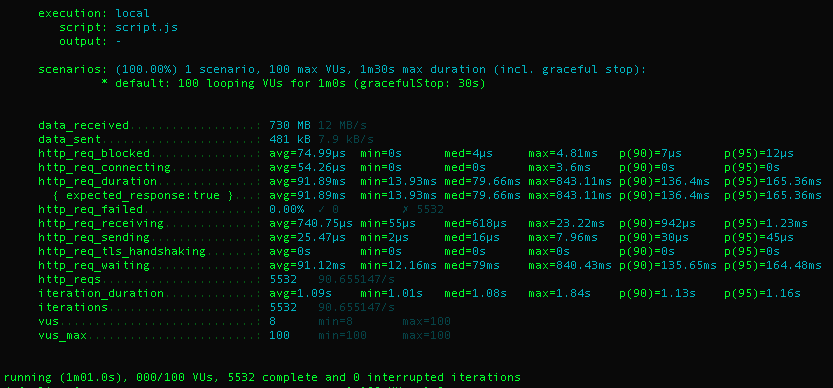
캐시 미적용
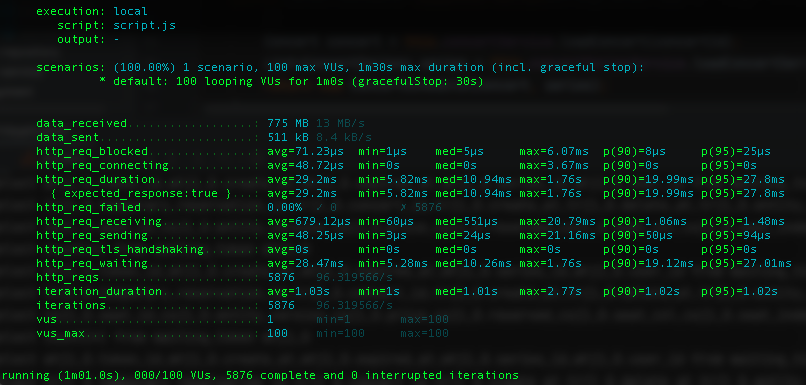
캐시 적용
캐시 없음
캐시 있음
차이
수신 데이터
730 MB (12 MB/s)
775 MB (13 MB/s)
+45 MB (+1 MB/s)
송신 데이터
481 KB (7.9 KB/s)
511 KB (8.4 KB/s)
+30 KB (+0.5 KB/s)
HTTP 요청 수
5532
5876
+344
반복 기간
평균=1.09초, 중간=1.01초, 최대=1.84초
평균=1.03초, 중간=1.01초, 최대=2.775초
-0.06초, 0초, +0.935초
HTTP 요청 대기 중
평균=91.12ms, 중간=12.16ms, 최대=840.43ms
평균=28.47ms, 중간=5.28ms, 최대=1.766초
-62.65ms, -6.88ms, +925.57ms
동일한 환경 100명의 가상 유저가 1분 동안 요청을 한경우 캐시를 사용할 경우 평균 HTTP요청 대기시간이 크게 줄고, 요청 수를 더 많이 처리한 것으로 보아 요청한 데이터를 응답받는 속도가 빠르단 것을 알 수 있었습니다.
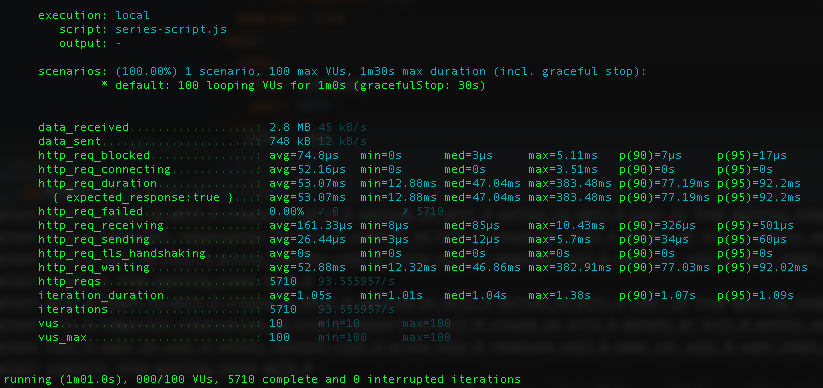
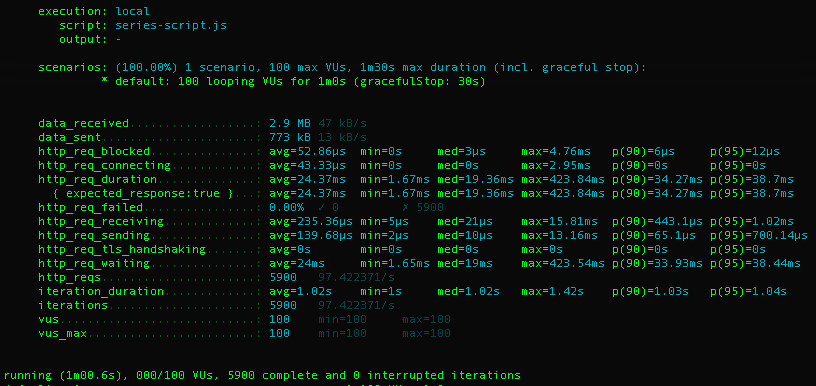
콘서트 시리즈 조회
ConcertSeries데이터 1000건을 사용하여 데이터를 저장하고 있으며, ConcertId로 검색하여 조회합니다.
캐시 미적용
캐시 적용
캐시 없음
캐시 있음
차이
수신 데이터
2.8 MB (45 kB/s)
2.9 MB (47 kB/s)
+0.1 MB (+2 kB/s)
송신 데이터
748 KB (12 KB/s)
773 KB (13 KB/s)
+25 KB (+1 KB/s)
HTTP 요청 수
5710
5900
+290
반복 기간
평균=1.05초, 중간=1.01초, 최대=1.38초
평균=1.02초, 중간=1.초, 최대=1.42초
-0.03초, 0.01초, +0.6초
HTTP 요청 대기 중
평균=52.88ms, 중간=12.32ms, 최대=382.91ms
평균=24ms, 중간=1.65ms, 최대=423.54ms
-28.88ms, -10.67ms, +40.63ms
100명의 유저가 1분동안 콘서트 아이디로 시리즈를 조회하였을 때를 환경으로 설정하여 테스트해 보았습니다.
캐시를 적용하기 전보다 290건의 트래픽을 수용할 수 있는 것으로 보아 서버 성능이 향상되었음을 확인할 수 있었습니다.
위 2건의 캐시 적용사례를 확인해 보면 동일한 유저와 동일한 시간 동안 요청을 보냈을 때 더 많은 요청을 수용할 수 있는 것을 확인할 수 있었습니다.
단순 Query로 인해 성능적 차이가 크게 보이지 않았지만, 복잡한 검색기능을 도입할 시 큰 차이를 보이게 될 것이라 생각됩니다.
추후 다이내믹한 검색 조건을 추가하여 캐싱을 적용하였을 때 복잡한 Query에 대한 성능 분석을 추가적으로 작성하도록 하겠습니다.
public class PointJpo {
@Id
private String userId;
@Version
private int entityVersion;
private int point;
}
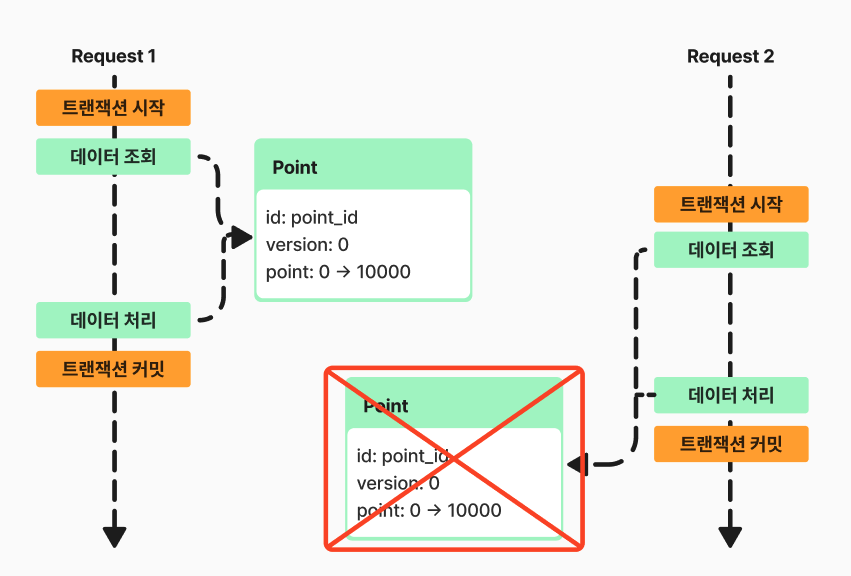
낙관적 락의 장점으로는 가장 간단하게 적용할 수 있고, 실제 DB락을 사용하지 않아 DB부하가 심하지 않다는 장점이 존재한다 생각합니다.
낙관적 락은 Update할 때 해당 데이터를 조회하여 version이 동일하다면 pass 다르다면 fail처리를 하는 Flow를 가지고 있습니다.
이로써 Transaction이 종료될 때 Update query가 발행되며 검사하는 만큼 Transaction초기에 해당 데이터의 일관성을 판단하고 Exception을 발생시키는 로직보다는 늦게 검증한다는 단점이 존재합니다.
또한 낙관적 락은 동시성을 처리할 때 처음 한번 수정이 이뤄졌다면, 나머지 동시에 요청된 트래픽들은 버전이 다르다면 전부 실패처리 해버려 충돌이 심한 로직의 경우 데이터의 수정에 있어 정확한 데이터를 얻을 수 있을 것이라는 보장이 힘들다 생각합니다.
그리고, 낙관적 락은 버전이 다를 경우 실패 처리해버리기 때문에 Retry를 사용하는 경우가 많은데, 이는 과한 메모리 사용등으로 인해 성능 저하를 일으킬 수 있으므로 적절한 상황을 염두하고 사용해야 합니다.
하여 낙관적 락은 초기 요청을 제외한 나머지 요청들이 실패하고, 충돌이 심하지 않은 곳에 사용하기 적절하다 생각합니다.
Pessimistic Lock( 비관적 락 )
@Lock을 활용한 비관적 락을 사용한 테스트입니다.
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from PointJpo p where p.userId = :id")
Optional<PointJpo> findByIdForLock(String id);
Point를 Charge 할 때 비관적 락을 적용하여 Lock을 걸었고, 배타 락( X-Lock )을 적용하여 데이터의 일관성을 보장하였습니다.
요청한 트래픽들이 대기하다 하나씩 수행되며, DB락을 걸어 DeadLock 발생 위험이 존재합니다.
공유 락 ( S-Lock )을 적용하였을 경우 DeadLock의 발생 빈도가 높아 비관적 락을 적용하여 테스트할 때는 배타 락을 사용하여 테스트하였습니다.
비관적 락은 들어온 요청들에 대해 DeadLock이 발생하지 않으면 모두 수행하는 만큼 충돌이 잦아도 이를 허용할 수 있다 생각합니다.
그리하여 초기 요청을 제외한 나머지 요청은 실패 처리하는 것이 아닌 나머지 요청들도 작업이 이뤄져야 할 경우 사용하는 것이 적절하다 생각합니다.
Distrubuted Lock ( 분산 락 )
Redis를 활용한 분산락입니다.
분산락은 Lettuce를 사용한 심플 락과 Redisson을 사용한 Pub/Sub방식으로 구현 및 테스트를 진행해 보았습니다.
첫 번째로Lettuce를 사용한 심플 락입니다.
심플락의 경우 RedisTemplate를 사용하여 Redis에 Lock을 저장하고 해당 Lock을 받아 처리하고 UnLock을 하는 방법으로 진행하였습니다.
심플 락은 여러 개의 요청이 들어올 경우 동일한 Lock Key를 사용할 경우 하나의 요청만 Lock을 할당해 주고 나머지는 튕겨내는 방식으로 이루어지는 Lock입니다. 이후 Retry 로직을 통해 Spin Lock으로 변형하여 사용할 수 있습니다.
Point충전 테스트를 Simple Lock을 활용하여 구현한 결과입니다.
10개의 요청을 시도하였으며, 동일한 userId를 사용하여 하나의 요청을 제외하고 나머지는 실패함으로써 한 번만 요청이 실행된 것을 확인할 수 있습니다.
심플 락의 경우 락 획득 후 에러로 인해 락 점유 해제를 하지 않는 다면 락이 계속 점유되어있어 무한 로딩에 빠질 수 있다는 단점이 존재합니다.
이러한 점을 주의하셔서 락은 획득 후 n초 후 락 점유 해제가 되도록 처리 로직을 추가하는 것을 권장합니다.
Lock을 획득한 트래픽은 수행하고 실패한 트래픽은 실패하는 상황
두 번째로Redisson을 사용한 Pub/Sub 방식의 분산 락입니다.
Redisson의 경우 Pub/Sub방식을 사용하고 있으며, 내부적으로 retry로직이 포함되어 있습니다.
Lettuce와 다르게 Lock을 시도하는 최대시간, Lock획득 후 점유하는 최대 시간을 손쉽게 설정할 수 있어 예외 상황으로 발생하는 Lock해제 실패로 인한 무한로딩 상황을 방지할 수 있으며, Retry기능으로 인해 동일한 키를 가진 여러 트래픽들을 수용할 수 있습니다.
단점이라고 하면, 지정한 시간 이외 처리될 트래픽들은 유실될 가능성이 크다는 단점을 가지고 있습니다.
위 테스트 결과만 보더라도 10건 중 5건을 처리하고 지정한 Lock점유 시간을 초과하여 트래픽이 유실된 상황입니다.
분산락의 경우 낙관적 락과 비관적 락에 비해 성능이 좋은 편은 아니라 생각하였습니다.
하지만, 지속적으로 트래픽을 점유하지 않아 DB부하를 Redis로 분산하여 관리한다는 점,
그리고 다양하게 Lock을 처리하면서 낙관/비관적 락에 비해 Custom과 락 핸들링이 좀 더 자유로운 점을 보아 다양한 상황에서 사용할 수 있다 생각합니다.
결론
위의 다양한 테스트들에 근거하여 다음 장에서 판단하는 상황별 어떤 락을 사용하는 것이 적합한가에 대해 판단을 하였습니다.
상황별 적용할 Lock
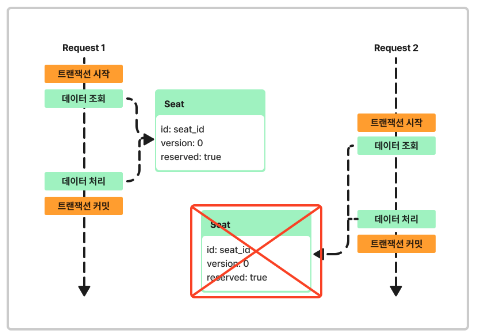
콘서트 좌석 신청 시 여러 명이 동시에 하나의 좌석을 요청하는 경우
적용 락: 낙관적 락 판단 근거: 콘서트 예약 즉 좌석 점유의 경우 한 명만 성공 처리하고 나머지는 실패처리를 하는 것이 정상적인 흐름이라고 판단하였습니다.
즉 비관적 락을 사용하여 동시성을 관리하는 것보다 Seat에 Version을 명시하여 Seat상태를 관리하는 방향으로 낙관적 락을 사용하는 것이 합당하다 생각하여 낙관적 락을 사용하겠습니다.
코드:
public class TemporaryReservationFlowFacade {
@LoggingPoint
@Transactional
public String createTemporaryReservation(
String userId,
String concertId,
String seriesId,
String seatId
) {
Concert concert = this.concertService.loadConcert(concertId);
// 콘서트 시리즈 조회
ConcertSeries concertSeries = this.concertSeriesService.loadConcertSeriesReservationAvailable(seriesId);
// 콘서트 좌석 조회
ConcertSeat concertSeat = this.concertSeatService.loadConcertSeatById(seatId);
// 좌석 예약
this.concertSeatService.reserveSeat(concertSeat.getSeatId());
// 임시 예약 생성
return this.temporaryReservationService.create(
userId,
concert.getConcertId(),
concert.getTitle(),
concertSeries.getSeriesId(),
concertSeat.getSeatId(),
concertSeat.getSeatRow(),
concertSeat.getSeatCol(),
concertSeat.getPrice()
);
}
}
테스트 결과
요청 유저 수: 100명 동시 접속 수: 100명 ( 동시 Thread 생성 수 10 ~ 15 ) 원하는 결과: 1명만 좌석 임시예약에 성공하고 나머지는 실패하는 케이스
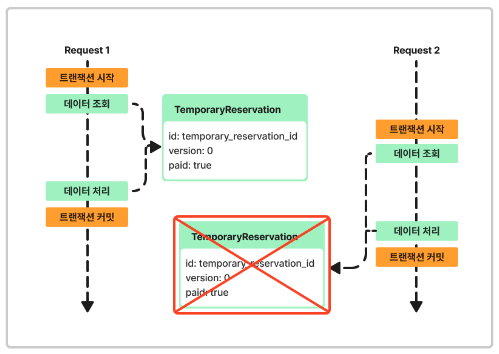
임시예약한 좌석을 결제 요청할 경우
적용 락: 낙관적 락 판단 근거: 임시 예약의 경우 결제를 하기 위해서는 본인이 신청한 좌석에 한해서 결제가 가능합니다.
즉 동시요청 상황의 경우 본인이 본인이 임시 예약한 정보를 결제요청하는 것이고, 이는 한번 성공하면 이후 요청에 있어 실패 처리를 하면 된다 생각합니다.
이때 TemporaryReservation에 paid라는 속성을 통해 결제 여부를 상태 관리하므로 낙관적 락을 통해 동시성을 처리하였습니다.
xxx@kafka:~/kafka_2.13-3.6.1$ ./bin/kafka-console-producer.sh --topic ${topicName:kafka-test} --bootstrap-server ${Address:localhost:9092}
>This is my first event
우선 일반 생성자로 만들고 Compile을 할 경우 아래와 같이 생성자 파라미터에 Qualifier로 어떤 Bean을 주입받을 것인지 명시가 되어있습니다.
@RestController
@RequestMapping({"/connect"})
public class ConnectTestController {
private final Test bean;
public ConnectTestController(@Qualifier("test1") Test bean) {
this.bean = bean;
}
@GetMapping
public String connect() {
System.out.println(this.bean.text);
return "OK";
}
}
아래 코드는 @RequiredArgsConstructord를 사용하여 만든 코드를 컴파일한 코드입니다.
@RestController
@RequestMapping({"/connect"})
public class ConnectTestController {
@Qualifier("test1")
private final Test bean;
@GetMapping
public String connect() {
System.out.println(this.bean.text);
return "OK";
}
public ConnectTestController(final Test bean) {
this.bean = bean;
}
}
다른 점이 보이시나요??
위 생성자를 직접 생성하여 Qualifier를 사용한 경우 생성자에 파라미터로 주입받을 때 명시적으로 붙어있지만 lombok에서 지원해 주는 어노테이션을 사용할 경우 final로 Test타입의 bean을 주입받겠다고 작성되어 있습니다.
이럴 경우 Bean의 명칭이 달라 test1으로 지정한 Bean을 주입받지 못하고 다른 Bean을 주입받거나 아예 못 받는 경우가 생기는 것입니다.
어떻게 해결할 수 있는가??
우선 가장 쉬운 방법은 위에 보여드린 것처럼 직접 생성자를 작성하는 방법이 있고, @Autowired를 사용하여 필드 주입을 해주는 방법이 존재합니다.
하지만 우리가 lombok을 사용하는 가장 큰 이유 코드를 덜 작성하고 싶다!! 는 니즈를 충족하는 방법이 있는데, 이는 lombok.config를 설정하는 것입니다.
src/main/java경로에 lombok.config파일을 생성 후 아래 코드를 작성해 주면 lombok에서 compile시 코드를 만들어 줄 때 해당 설정을 통해 Qualifier를 반영하여 생성해 주는 것을 확인할 수 있습니다.
@RestController
@RequestMapping({"/connect"})
public class ConnectTestController {
@Qualifier("test1")
private final Test bean;
@GetMapping
public String connect() {
System.out.println(this.bean.text);
return "OK";
}
public ConnectTestController(@Qualifier("test1") final Test bean) {
this.bean = bean;
}
}
해당 객체가 Bean으로 등록될 때 생성자에 명시되어 있는 파라미터들을 즉 Bean들을 주입받는 방식입니다.
가장 기본적이라 생각하며, 가장 코드 줄이 긴 방법이지만 가장 직관적인 만큼 오류가 가장 발생하지 않는 방법입니다.
@RestController
@RequestMapping("/connect")
public class ConnectTestController {
//
private final Test testDescription;
public ConnectTestController(Test testDescription) {
//주입받는 부분
this.testDescription = testDescription;
}
@GetMapping()
public String connect() {
System.out.println(testDescription.testDescription());
return "OK";
}
}
2. @RequiredArgsConstructor
lombok의 @RequiredArgsConstructor를 사용하는 방법입니다.
@RestController
@RequestMapping("/connect")
@RequiredArgsConstructor
public class ConnectTestController {
//
private final Test testDescription;
@GetMapping()
public String connect() {
System.out.println(testDescription.testDescription());
return "OK";
}
}
위와 같이 생성자를 직접 명시하지 않고 사용하는 방법이며 final로 지정된 전역변수들에 한해서 빈을 자동으로 주입해 줍니다.
3.@Autowired
위 방법들과 다르게 필드 주입 혹은 수정자 주입받을 때 사용하는 방법입니다.
기본적으로 Springframework에서 제공해 주는 @Autowired어노테이션을 사용합니다.
필드 주입
@RestController
@RequestMapping("/connect")
public class ConnectTestController {
//
@Autowired
private Test testDescription;
@GetMapping()
public String connect() {
System.out.println(testDescription.testDescription());
return "OK";
}
}
수정자 주입
@RestController
@RequestMapping("/connect")
public class ConnectTestController {
//
private Test testDescription;
@Autowired(required = false)
public void setTestDescription(Test testDescription) {
this.testDescription = testDescription;
}
@GetMapping()
public String connect() {
System.out.println(testDescription.testDescription());
return "OK";
}
}
위처럼 두 가지 방법으로 구현이 가능한 방법입니다.
생성자 주입방식보다 번거롭고 코드 줄이 길어 가독성이 불편하며, 개발자 실수가 많이 이뤄질 수 있는 방법으로 권장하는 Bean주입 방법은 생성자 주입방법을 권장하고 있습니다.
기타
@Qualifier
Qualifier은 동일한 타입의 Bean들이 많을 때 어떤 Bean을 주입받을지 명시할 때 사용하는 어노테이션입니다.
@Component
public class Test {
public String text = "test";
@Bean
@Qualifier("test1")
public Test testDescription() {
Test test = new Test();
test.text = "hello";
return test;
}
}
우선 Bean을 2개 지정해 보도록 하겠습니다. 하나는 Test라는 Bean이고 하나는 test1이라는 Bean을 등록하였습니다.
위처럼 @Qualifier를 지정하여 사용할 경우 해당 이름으로 Bean이 생성됩니다.
@RestController
@RequestMapping("/connect")
public class ConnectTestController {
//
@Autowired
@Qualifier("test1")
private Test bean;
@Autowired
private Test test;
@GetMapping()
public String connect() {
System.out.println(bean.text);
System.out.println(test.text);
return "OK";
}
}
이후 위처럼 각각 정의를 하고 실행을 하였을 때 아래와 같은 실험 결과를 얻어볼 수 있습니다.
이처럼 같은 타입을 반환하는 Bean들 중 하나를 지정하여 주입받을 때 사용하는 어노테이션입니다.
이것이 무슨 말이냐 우리가 기본적으로 사용하는 일반적인 HTTP 통신은 Client가 요청을 보내면 서버는 해당 요청 건에 대해서만 응답을 할 수 있는 규칙을 가지고 있습니다.
이럴 경우 우리가 개발한 서버에서 어떤 작업이 이뤄졌을 때 Client가 알 수 있는 방법은 Client의 요청이 있을 때까지 기다리는 방법 밖에는 없습니다. 하지만 이렇게 구현을 하자면 Client는 일정 시간이 지날 때마다 서버를 조회하여 데이터를 최신화 시켜주는 방법 밖에 없을 것이고 이는 무분별한 호출로 인한 리소스 낭비로 인해 문제를 야기할 수도 있습니다.
그럼 서버에서 응답을 보내서 Client에서 처리하면 어떨까? 해서 나온 것이 웹소켓과 SSE기술입니다.
웹소켓의 경우 양방향 통신으로 handshaking방식으로 이루어집니다. 이는 Client와 서버의 통신이 연결되는 방식을 말하며 웹소켓에서 한번 연결된 통신은 지속적으로 유지되며, 이 통신을 통해 Client와 서버는 데이터를 주고 받을 수 있습니다. 이는 채팅과 같이 실시간 소통이 이뤄져야하는 기능을 구현 할 때 많이 사용되는 방법입니다.
하지만 알람과 같이 Client가 서버로 요청을 보내지 않아도 서버에서 특정 작업이 생겼을 때 Client가 알게 하고 싶다면 WebSocket방식은 과한 기능 구현인 것 같을 수 있습니다. 그럴때는 SSE를 적용하는 것을 고민해볼 수 있습니다.
SSE는 Client의 요청을 기다리지 않고 서버에서 Client로 요청을 보내는 기술로 서버에서 단방향 통신으로 Client로 응답을 보낼 수 있습니다. Client가 처음 한번의 요청을 통해 Client와 서버의 연결이 설정된 후 서버의 일방적인 데이터 전송이 가능해 집니다.
사용방법(Client - React)
Client의 설정은 간단합니다. 위에서 말했듯 Client에서의 작업은 초기 연결 설정을 위한 요청과 Event를 수신하여 작업할 부분만 작업해주면 됩니다.
useEffect(() => {
let eventSource: EventSource;
if (requestId.length) {
// 서버와 연결
eventSource = new EventSource(defaultURL + "/connect/" + requestId);
// 이벤트 수신 시 수행할 작업들
eventSource.addEventListener("message", handleEventMessage);
eventSource.addEventListener("error", handleEventError);
}
return (() => {
if (requestId) {
// 페이지가 종료될 때 설정한 이벤트들도 제거
eventSource.removeEventListener("message", handleEventMessage);
eventSource.removeEventListener("error", handleEventError);
}
})
}, [requestId]);
위 설정은 서버와의 초기 연결을 요청 보내는 부분입니다.
new EventSource()는 초기 서버 연결을 담당해주는 부분이며, 내부 파라미터로 url을 주입해주면 해당 URL로 Get요청을 보내줍니다.
이때 요청 Header의 Content-Type은 text/event-stream으로 지정되어 있습니다.
사용방법(Back-Spring)
서버는 Client보다 작업량 자체는 많지만 다른 웹소켓과 같은 기술들에 비하면 훨씬 적은 설정으로 구현할 수 있습니다.
우선 서버는 Client로부터 연결을 위한 요청이 들어온다면 HTTP Method와 produces즉 미디어 타입을 명시 해주어야합니다.
@GetMapping(value = "/connect/{requestId}", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter connect(@PathVariable String requestId) {
// SseEmitter설정을 위해 sseService의 register을 사용
return sseService.register(requestId);
}