728x90
마이크로서비스 아키텍처(MSA)에서 각 서비스는 독립적으로 운영되지만, 사용자에게 일관된 알림 경험을 제공해야 합니다. 주문 완료, 결제 승인, 배송 시작 등 다양한 이벤트가 발생할 때마다 이메일, SMS, 푸시 알림을 통해 사용자에게 적절한 정보를 전달해야 하죠.
이번 글에서는 Spring Boot와 MySQL을 사용하여 MSA 환경에서 효율적인 알림 서비스를 설계하고 구현하는 방법을 살펴보겠습니다.
예제 시나리오
온라인 쇼핑몰의 다음 서비스들이 알림을 발송해야 하는 상황을 가정하겠습니다:
- 주문 서비스: 주문 완료, 주문 취소 알림
- 결제 서비스: 결제 완료, 결제 실패 알림
- 배송 서비스: 배송 시작, 배송 완료 알림
- 회원 서비스: 회원 가입 환영, 비밀번호 변경 알림
알림 서비스 아키텍처
전체 구조도
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ Order Service │ │ Payment Service │ │Shipping Service │
│ │ │ │ │ │
│ ┌──────────┐ │ │ ┌──────────┐ │ │ ┌──────────┐ │
│ │Event Pub │ │ │ │Event Pub │ │ │ │Event Pub │ │
│ └──────────┘ │ │ └──────────┘ │ │ └──────────┘ │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
└───────────────────────┼───────────────────────┘
│
┌─────────────────────────────┐
│ Message Queue │
│ (RabbitMQ) │
└─────────────────────────────┘
│
┌─────────────────────────────┐
│ Notification Service │
│ │
│ ┌─────────────────────┐ │
│ │ Event Processor │ │
│ └─────────────────────┘ │
│ ┌─────────────────────┐ │
│ │ Template Engine │ │
│ └─────────────────────┘ │
│ ┌─────────────────────┐ │
│ │ Channel Router │ │
│ └─────────────────────┘ │
└─────────────────────────────┘
│
┌────────────────────┼────────────────────┐
│ │ │
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Email Service │ │ SMS Service │ │ Push Service │
│ (SMTP) │ │ (Twilio) │ │ (FCM) │
└───────────────┘ └───────────────┘ └───────────────┘시퀀스 다이어그램
┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│Order Service│ │Message Queue│ │Notification │ │ Template │ │Email Service│
│ │ │ │ │ Service │ │ Engine │ │ │
└─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘
│ │ │ │ │
│ 1. Publish │ │ │ │
│ OrderComplete │ │ │ │
│ Event │ │ │ │
│──────────────→│ │ │ │
│ │ │ │ │
│ │ 2. Consume │ │ │
│ │ Event │ │ │
│ │──────────────→│ │ │
│ │ │ │ │
│ │ │ 3. Load │ │
│ │ │ Template │ │
│ │ │──────────────→│ │
│ │ │ │ │
│ │ │ 4. Generate │ │
│ │ │ Content │ │
│ │ │←──────────────│ │
│ │ │ │ │
│ │ │ 5. Send │ │
│ │ │ Notification │ │
│ │ │──────────────────────────────→│
│ │ │ │ │
│ │ │ 6. Update │ │
│ │ │ Status │ │
│ │ │──────────────→│ │데이터베이스 설계
알림 관련 테이블 구조
-- 알림 템플릿 테이블
CREATE TABLE notification_template (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
template_code VARCHAR(50) NOT NULL UNIQUE,
template_name VARCHAR(100) NOT NULL,
channel_type ENUM('EMAIL', 'SMS', 'PUSH') NOT NULL,
subject VARCHAR(200),
content TEXT NOT NULL,
variables JSON,
is_active BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 알림 요청 테이블
CREATE TABLE notification_request (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
event_id VARCHAR(100) NOT NULL,
event_type VARCHAR(50) NOT NULL,
user_id BIGINT NOT NULL,
template_code VARCHAR(50) NOT NULL,
channel_type ENUM('EMAIL', 'SMS', 'PUSH') NOT NULL,
recipient VARCHAR(200) NOT NULL,
variables JSON,
status ENUM('PENDING', 'PROCESSING', 'SENT', 'FAILED') DEFAULT 'PENDING',
retry_count INT DEFAULT 0,
error_message TEXT,
sent_at TIMESTAMP NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_status_created (status, created_at),
INDEX idx_user_id (user_id),
INDEX idx_event_type (event_type)
);
-- 알림 발송 이력 테이블
CREATE TABLE notification_history (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
request_id BIGINT NOT NULL,
channel_type ENUM('EMAIL', 'SMS', 'PUSH') NOT NULL,
recipient VARCHAR(200) NOT NULL,
subject VARCHAR(200),
content TEXT,
status ENUM('SENT', 'FAILED') NOT NULL,
provider VARCHAR(50),
external_id VARCHAR(100),
error_message TEXT,
sent_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (request_id) REFERENCES notification_request(id),
INDEX idx_request_id (request_id),
INDEX idx_sent_at (sent_at)
);
-- 사용자 알림 설정 테이블
CREATE TABLE user_notification_preference (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id BIGINT NOT NULL,
event_type VARCHAR(50) NOT NULL,
channel_type ENUM('EMAIL', 'SMS', 'PUSH') NOT NULL,
is_enabled BOOLEAN DEFAULT TRUE,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
UNIQUE KEY uk_user_event_channel (user_id, event_type, channel_type),
INDEX idx_user_id (user_id)
);Spring Boot 알림 서비스 구현
1. 도메인 모델 정의
// 알림 요청 엔티티
@Entity
@Table(name = "notification_request")
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class NotificationRequest {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "event_id", nullable = false)
private String eventId;
@Column(name = "event_type", nullable = false)
private String eventType;
@Column(name = "user_id", nullable = false)
private Long userId;
@Column(name = "template_code", nullable = false)
private String templateCode;
@Enumerated(EnumType.STRING)
@Column(name = "channel_type", nullable = false)
private ChannelType channelType;
@Column(name = "recipient", nullable = false)
private String recipient;
@Convert(converter = JpaConverterJson.class)
@Column(name = "variables", columnDefinition = "JSON")
private Map<String, Object> variables;
@Enumerated(EnumType.STRING)
@Column(name = "status")
private NotificationStatus status = NotificationStatus.PENDING;
@Column(name = "retry_count")
private Integer retryCount = 0;
@Column(name = "error_message")
private String errorMessage;
@Column(name = "sent_at")
private LocalDateTime sentAt;
@CreatedDate
@Column(name = "created_at")
private LocalDateTime createdAt;
@LastModifiedDate
@Column(name = "updated_at")
private LocalDateTime updatedAt;
}
// 알림 템플릿 엔티티
@Entity
@Table(name = "notification_template")
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class NotificationTemplate {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "template_code", unique = true, nullable = false)
private String templateCode;
@Column(name = "template_name", nullable = false)
private String templateName;
@Enumerated(EnumType.STRING)
@Column(name = "channel_type", nullable = false)
private ChannelType channelType;
@Column(name = "subject")
private String subject;
@Column(name = "content", nullable = false, columnDefinition = "TEXT")
private String content;
@Convert(converter = JpaConverterJson.class)
@Column(name = "variables", columnDefinition = "JSON")
private List<String> variables;
@Column(name = "is_active")
private Boolean isActive = true;
@CreatedDate
@Column(name = "created_at")
private LocalDateTime createdAt;
@LastModifiedDate
@Column(name = "updated_at")
private LocalDateTime updatedAt;
}
// 열거형 정의
public enum ChannelType {
EMAIL, SMS, PUSH
}
public enum NotificationStatus {
PENDING, PROCESSING, SENT, FAILED
}2. 이벤트 메시지 정의
// 기본 알림 이벤트
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class NotificationEvent {
private String eventId;
private String eventType;
private Long userId;
private String userEmail;
private String userPhone;
private Map<String, Object> data;
private List<ChannelType> channels;
private LocalDateTime occurredAt;
}
// 주문 완료 이벤트
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class OrderCompletedEvent {
private String orderId;
private Long userId;
private String userEmail;
private String customerName;
private String productName;
private BigDecimal totalAmount;
private String orderDate;
private String deliveryAddress;
private LocalDateTime occurredAt;
public NotificationEvent toNotificationEvent() {
Map<String, Object> data = Map.of(
"orderId", orderId,
"customerName", customerName,
"productName", productName,
"totalAmount", totalAmount,
"orderDate", orderDate,
"deliveryAddress", deliveryAddress
);
return NotificationEvent.builder()
.eventId(orderId)
.eventType("ORDER_COMPLETED")
.userId(userId)
.userEmail(userEmail)
.data(data)
.channels(Arrays.asList(ChannelType.EMAIL, ChannelType.SMS))
.occurredAt(occurredAt)
.build();
}
}3. 메시지 큐 설정
@Configuration
@EnableRabbit
public class RabbitMQConfig {
public static final String NOTIFICATION_EXCHANGE = "notification.exchange";
public static final String NOTIFICATION_QUEUE = "notification.queue";
public static final String NOTIFICATION_ROUTING_KEY = "notification.event";
@Bean
public TopicExchange notificationExchange() {
return new TopicExchange(NOTIFICATION_EXCHANGE);
}
@Bean
public Queue notificationQueue() {
return QueueBuilder.durable(NOTIFICATION_QUEUE)
.withArgument("x-dead-letter-exchange", NOTIFICATION_EXCHANGE + ".dlx")
.withArgument("x-dead-letter-routing-key", "notification.failed")
.build();
}
@Bean
public Binding notificationBinding() {
return BindingBuilder
.bind(notificationQueue())
.to(notificationExchange())
.with(NOTIFICATION_ROUTING_KEY);
}
@Bean
public RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) {
RabbitTemplate template = new RabbitTemplate(connectionFactory);
template.setMessageConverter(new Jackson2JsonMessageConverter());
template.setExchange(NOTIFICATION_EXCHANGE);
return template;
}
}4. 알림 이벤트 발행자 (각 서비스에서 사용)
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationEventPublisher {
private final RabbitTemplate rabbitTemplate;
public void publishOrderCompleted(OrderCompletedEvent event) {
try {
NotificationEvent notificationEvent = event.toNotificationEvent();
rabbitTemplate.convertAndSend(
RabbitMQConfig.NOTIFICATION_ROUTING_KEY,
notificationEvent
);
log.info("Order completed event published: {}", event.getOrderId());
} catch (Exception e) {
log.error("Failed to publish order completed event: {}", event.getOrderId(), e);
}
}
public void publishPaymentCompleted(PaymentCompletedEvent event) {
try {
NotificationEvent notificationEvent = event.toNotificationEvent();
rabbitTemplate.convertAndSend(
RabbitMQConfig.NOTIFICATION_ROUTING_KEY,
notificationEvent
);
log.info("Payment completed event published: {}", event.getPaymentId());
} catch (Exception e) {
log.error("Failed to publish payment completed event: {}", event.getPaymentId(), e);
}
}
}5. 알림 서비스 핵심 구현
// 알림 이벤트 리스너
@Component
@RequiredArgsConstructor
@Slf4j
public class NotificationEventListener {
private final NotificationProcessingService notificationProcessingService;
@RabbitListener(queues = RabbitMQConfig.NOTIFICATION_QUEUE)
public void handleNotificationEvent(NotificationEvent event) {
try {
log.info("Received notification event: {} for user: {}",
event.getEventType(), event.getUserId());
notificationProcessingService.processNotification(event);
} catch (Exception e) {
log.error("Failed to process notification event: {}", event.getEventId(), e);
throw new AmqpRejectAndDontRequeueException("Failed to process notification", e);
}
}
}
// 알림 처리 서비스
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationProcessingService {
private final NotificationRequestRepository notificationRequestRepository;
private final NotificationTemplateRepository templateRepository;
private final UserNotificationPreferenceRepository preferenceRepository;
private final NotificationChannelRouter channelRouter;
@Transactional
public void processNotification(NotificationEvent event) {
// 1. 사용자 알림 설정 확인
List<UserNotificationPreference> preferences =
preferenceRepository.findByUserIdAndEventType(event.getUserId(), event.getEventType());
Map<ChannelType, Boolean> enabledChannels = preferences.stream()
.collect(Collectors.toMap(
UserNotificationPreference::getChannelType,
UserNotificationPreference::getIsEnabled
));
// 2. 활성화된 채널별로 알림 요청 생성
for (ChannelType channel : event.getChannels()) {
if (enabledChannels.getOrDefault(channel, true)) {
createNotificationRequest(event, channel);
}
}
}
private void createNotificationRequest(NotificationEvent event, ChannelType channel) {
try {
String templateCode = generateTemplateCode(event.getEventType(), channel);
String recipient = getRecipient(event, channel);
NotificationRequest request = NotificationRequest.builder()
.eventId(event.getEventId())
.eventType(event.getEventType())
.userId(event.getUserId())
.templateCode(templateCode)
.channelType(channel)
.recipient(recipient)
.variables(event.getData())
.status(NotificationStatus.PENDING)
.build();
notificationRequestRepository.save(request);
// 비동기로 알림 발송 처리
channelRouter.routeNotification(request);
} catch (Exception e) {
log.error("Failed to create notification request: {} for channel: {}",
event.getEventId(), channel, e);
}
}
private String generateTemplateCode(String eventType, ChannelType channel) {
return eventType + "_" + channel.name();
}
private String getRecipient(NotificationEvent event, ChannelType channel) {
switch (channel) {
case EMAIL:
return event.getUserEmail();
case SMS:
return event.getUserPhone();
case PUSH:
return event.getUserId().toString();
default:
throw new IllegalArgumentException("Unsupported channel type: " + channel);
}
}
}6. 템플릿 엔진 구현
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationTemplateEngine {
private final NotificationTemplateRepository templateRepository;
public NotificationContent generateContent(String templateCode, Map<String, Object> variables) {
NotificationTemplate template = templateRepository.findByTemplateCodeAndIsActiveTrue(templateCode)
.orElseThrow(() -> new NotificationTemplateNotFoundException(templateCode));
String processedSubject = processTemplate(template.getSubject(), variables);
String processedContent = processTemplate(template.getContent(), variables);
return NotificationContent.builder()
.subject(processedSubject)
.content(processedContent)
.channelType(template.getChannelType())
.build();
}
private String processTemplate(String template, Map<String, Object> variables) {
if (template == null) {
return null;
}
String result = template;
for (Map.Entry<String, Object> entry : variables.entrySet()) {
String placeholder = "{{" + entry.getKey() + "}}";
String value = entry.getValue() != null ? entry.getValue().toString() : "";
result = result.replace(placeholder, value);
}
return result;
}
}
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class NotificationContent {
private String subject;
private String content;
private ChannelType channelType;
}7. 채널별 발송 서비스
// 채널 라우터
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationChannelRouter {
private final Map<ChannelType, NotificationChannelService> channelServices;
private final NotificationRequestRepository requestRepository;
@Async
public void routeNotification(NotificationRequest request) {
try {
// 상태를 PROCESSING으로 업데이트
request.setStatus(NotificationStatus.PROCESSING);
requestRepository.save(request);
NotificationChannelService channelService = channelServices.get(request.getChannelType());
if (channelService == null) {
throw new UnsupportedChannelException(request.getChannelType());
}
channelService.sendNotification(request);
} catch (Exception e) {
log.error("Failed to route notification: {}", request.getId(), e);
handleFailure(request, e);
}
}
private void handleFailure(NotificationRequest request, Exception e) {
request.setStatus(NotificationStatus.FAILED);
request.setErrorMessage(e.getMessage());
request.setRetryCount(request.getRetryCount() + 1);
requestRepository.save(request);
// 재시도 로직 (간단한 구현)
if (request.getRetryCount() < 3) {
// 지연 후 재시도 (실제로는 더 정교한 재시도 전략 필요)
CompletableFuture.delayedExecutor(Duration.ofMinutes(5))
.execute(() -> routeNotification(request));
}
}
}
// 이메일 발송 서비스
@Service
@RequiredArgsConstructor
@Slf4j
public class EmailNotificationService implements NotificationChannelService {
private final JavaMailSender mailSender;
private final NotificationTemplateEngine templateEngine;
private final NotificationRequestRepository requestRepository;
private final NotificationHistoryRepository historyRepository;
@Override
public void sendNotification(NotificationRequest request) {
try {
NotificationContent content = templateEngine.generateContent(
request.getTemplateCode(), request.getVariables());
MimeMessage message = mailSender.createMimeMessage();
MimeMessageHelper helper = new MimeMessageHelper(message, true, "UTF-8");
helper.setTo(request.getRecipient());
helper.setSubject(content.getSubject());
helper.setText(content.getContent(), true);
helper.setFrom("noreply@example.com");
mailSender.send(message);
// 성공 처리
request.setStatus(NotificationStatus.SENT);
request.setSentAt(LocalDateTime.now());
requestRepository.save(request);
// 발송 이력 저장
saveHistory(request, content, NotificationStatus.SENT, null);
log.info("Email notification sent successfully: {}", request.getId());
} catch (Exception e) {
log.error("Failed to send email notification: {}", request.getId(), e);
// 실패 처리
request.setStatus(NotificationStatus.FAILED);
request.setErrorMessage(e.getMessage());
requestRepository.save(request);
saveHistory(request, null, NotificationStatus.FAILED, e.getMessage());
throw new NotificationSendException("Failed to send email", e);
}
}
private void saveHistory(NotificationRequest request, NotificationContent content,
NotificationStatus status, String errorMessage) {
NotificationHistory history = NotificationHistory.builder()
.requestId(request.getId())
.channelType(request.getChannelType())
.recipient(request.getRecipient())
.subject(content != null ? content.getSubject() : null)
.content(content != null ? content.getContent() : null)
.status(status)
.provider("SMTP")
.errorMessage(errorMessage)
.sentAt(LocalDateTime.now())
.build();
historyRepository.save(history);
}
}
// SMS 발송 서비스 (Twilio 예제)
@Service
@RequiredArgsConstructor
@Slf4j
public class SmsNotificationService implements NotificationChannelService {
private final NotificationTemplateEngine templateEngine;
private final NotificationRequestRepository requestRepository;
private final NotificationHistoryRepository historyRepository;
@Value("${twilio.account.sid}")
private String accountSid;
@Value("${twilio.auth.token}")
private String authToken;
@Value("${twilio.phone.number}")
private String fromPhoneNumber;
@Override
public void sendNotification(NotificationRequest request) {
try {
Twilio.init(accountSid, authToken);
NotificationContent content = templateEngine.generateContent(
request.getTemplateCode(), request.getVariables());
Message message = Message.creator(
new PhoneNumber(request.getRecipient()),
new PhoneNumber(fromPhoneNumber),
content.getContent())
.create();
// 성공 처리
request.setStatus(NotificationStatus.SENT);
request.setSentAt(LocalDateTime.now());
requestRepository.save(request);
// 발송 이력 저장
saveHistory(request, content, NotificationStatus.SENT, null, message.getSid());
log.info("SMS notification sent successfully: {}", request.getId());
} catch (Exception e) {
log.error("Failed to send SMS notification: {}", request.getId(), e);
// 실패 처리
request.setStatus(NotificationStatus.FAILED);
request.setErrorMessage(e.getMessage());
requestRepository.save(request);
saveHistory(request, null, NotificationStatus.FAILED, e.getMessage(), null);
throw new NotificationSendException("Failed to send SMS", e);
}
}
private void saveHistory(NotificationRequest request, NotificationContent content,
NotificationStatus status, String errorMessage, String externalId) {
NotificationHistory history = NotificationHistory.builder()
.requestId(request.getId())
.channelType(request.getChannelType())
.recipient(request.getRecipient())
.content(content != null ? content.getContent() : null)
.status(status)
.provider("TWILIO")
.externalId(externalId)
.errorMessage(errorMessage)
.sentAt(LocalDateTime.now())
.build();
historyRepository.save(history);
}
}8. 실제 사용 예제
// 주문 서비스에서 알림 발송
@Service
@RequiredArgsConstructor
@Slf4j
public class OrderService {
private final NotificationEventPublisher notificationPublisher;
private final OrderRepository orderRepository;
@Transactional
public void completeOrder(Long orderId) {
Order order = orderRepository.findById(orderId)
.orElseThrow(() -> new OrderNotFoundException(orderId));
// 주문 상태 업데이트
order.setStatus(OrderStatus.COMPLETED);
order.setCompletedAt(LocalDateTime.now());
orderRepository.save(order);
// 알림 이벤트 발행
OrderCompletedEvent event = OrderCompletedEvent.builder()
.orderId(order.getId().toString())
.userId(order.getUserId())
.userEmail(order.getUserEmail())
.customerName(order.getCustomerName())
.productName(order.getProductName())
.totalAmount(order.getTotalAmount())
.orderDate(order.getOrderDate().toString())
.deliveryAddress(order.getDeliveryAddress())
.occurredAt(LocalDateTime.now())
.build();
notificationPublisher.publishOrderCompleted(event);
log.info("Order completed and notification event published: {}", orderId);
}
}
// 알림 템플릿 등록 예제
@Component
@RequiredArgsConstructor
@Slf4j
public class NotificationTemplateInitializer {
private final NotificationTemplateRepository templateRepository;
@PostConstruct
public void initializeTemplates() {
createOrderCompletedEmailTemplate();
createOrderCompletedSmsTemplate();
}
private void createOrderCompletedEmailTemplate() {
String emailContent = """
<html>
<body>
<h2>주문이 완료되었습니다!</h2>
<p>안녕하세요, {{customerName}}님!</p>
<p>주문해주신 상품의 주문이 성공적으로 완료되었습니다.</p>
<div style="border: 1px solid #ddd; padding: 20px; margin: 20px 0;">
<h3>주문 정보</h3>
<p><strong>주문 번호:</strong> {{orderId}}</p>
<p><strong>상품명:</strong> {{productName}}</p>
<p><strong>결제 금액:</strong> {{totalAmount}}원</p>
<p><strong>주문 날짜:</strong> {{orderDate}}</p>
<p><strong>배송 주소:</strong> {{deliveryAddress}}</p>
</div>
<p>빠른 시일 내에 배송 준비를 완료하겠습니다.</p>
<p>감사합니다.</p>
</body>
</html>
""";
NotificationTemplate template = NotificationTemplate.builder()
.templateCode("ORDER_COMPLETED_EMAIL")
.templateName("주문 완료 이메일")
.channelType(ChannelType.EMAIL)
.subject("주문이 완료되었습니다 - 주문번호: {{orderId}}")
.content(emailContent)
.variables(Arrays.asList("customerName", "orderId", "productName",
"totalAmount", "orderDate", "deliveryAddress"))
.isActive(true)
.build();
templateRepository.save(template);
log.info("Order completed email template created");
}
private void createOrderCompletedSmsTemplate() {
String smsContent = """
[쇼핑몰] {{customerName}}님, 주문이 완료되었습니다.
주문번호: {{orderId}}
상품: {{productName}}
금액: {{totalAmount}}원
배송지: {{deliveryAddress}}
감사합니다.
""";
NotificationTemplate template = NotificationTemplate.builder()
.templateCode("ORDER_COMPLETED_SMS")
.templateName("주문 완료 SMS")
.channelType(ChannelType.SMS)
.content(smsContent)
.variables(Arrays.asList("customerName", "orderId", "productName",
"totalAmount", "deliveryAddress"))
.isActive(true)
.build();
templateRepository.save(template);
log.info("Order completed SMS template created");
}
}알림 서비스의 장점
1. 확장성과 유연성
- 독립적 확장: 알림 서비스는 다른 서비스와 독립적으로 스케일링 가능
- 채널 추가 용이: 새로운 알림 채널(카카오톡, 슬랙 등) 추가 시 기존 코드 변경 최소화
- 템플릿 관리: 운영자가 직접 알림 내용을 수정할 수 있는 템플릿 시스템
2. 안정성과 복원력
- 비동기 처리: 메시지 큐를 통한 비동기 처리로 메인 서비스 성능에 영향 없음
- 재시도 메커니즘: 실패한 알림에 대한 자동 재시도 기능
- 장애 격리: 알림 서비스 장애가 다른 서비스에 영향을 주지 않음
3. 운영 효율성
- 중앙 집중 관리: 모든 알림을 한 곳에서 관리하고 모니터링
- 발송 이력 추적: 완전한 알림 발송 이력과 상태 추적 가능
- 사용자 설정: 사용자별 알림 수신 설정 관리
알림 서비스 구현 시 고려사항
1. 성능 최적화
// 배치 처리를 통한 성능 개선
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationBatchProcessor {
private final NotificationRequestRepository requestRepository;
private final NotificationChannelRouter channelRouter;
@Scheduled(fixedDelay = 5000) // 5초마다 실행
public void processPendingNotifications() {
List<NotificationRequest> pendingRequests =
requestRepository.findByStatusOrderByCreatedAtAsc(
NotificationStatus.PENDING, PageRequest.of(0, 100));
if (!pendingRequests.isEmpty()) {
log.info("Processing {} pending notifications", pendingRequests.size());
// 채널별로 그룹화하여 병렬 처리
Map<ChannelType, List<NotificationRequest>> groupedRequests =
pendingRequests.stream()
.collect(Collectors.groupingBy(NotificationRequest::getChannelType));
groupedRequests.forEach((channelType, requests) -> {
CompletableFuture.runAsync(() -> {
requests.forEach(channelRouter::routeNotification);
});
});
}
}
}2. 모니터링 및 알림
// 알림 서비스 모니터링
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationMonitoringService {
private final NotificationRequestRepository requestRepository;
private final MeterRegistry meterRegistry;
@EventListener
public void handleNotificationSent(NotificationSentEvent event) {
// 메트릭 수집
Counter.builder("notification.sent")
.tag("channel", event.getChannelType().name())
.tag("event_type", event.getEventType())
.register(meterRegistry)
.increment();
}
@EventListener
public void handleNotificationFailed(NotificationFailedEvent event) {
// 실패 메트릭 수집
Counter.builder("notification.failed")
.tag("channel", event.getChannelType().name())
.tag("event_type", event.getEventType())
.tag("error_type", event.getErrorType())
.register(meterRegistry)
.increment();
}
@Scheduled(fixedRate = 60000) // 1분마다 체크
public void checkNotificationHealth() {
long failedCount = requestRepository.countByStatusAndCreatedAtAfter(
NotificationStatus.FAILED,
LocalDateTime.now().minusMinutes(5)
);
if (failedCount > 10) {
log.warn("High notification failure rate detected: {} failures in last 5 minutes",
failedCount);
// 알림 또는 대시보드에 경고 전송
}
}
}3. 보안 고려사항
// 개인정보 보호를 위한 데이터 마스킹
@Service
@RequiredArgsConstructor
public class NotificationSecurityService {
public String maskPersonalInfo(String data, String type) {
if (data == null) return null;
switch (type) {
case "email":
return maskEmail(data);
case "phone":
return maskPhone(data);
default:
return data;
}
}
private String maskEmail(String email) {
if (email == null || !email.contains("@")) return email;
String[] parts = email.split("@");
String localPart = parts[0];
String domain = parts[1];
if (localPart.length() <= 2) return email;
return localPart.charAt(0) + "***" + localPart.charAt(localPart.length() - 1) + "@" + domain;
}
private String maskPhone(String phone) {
if (phone == null || phone.length() < 8) return phone;
return phone.substring(0, 3) + "****" + phone.substring(phone.length() - 4);
}
}실제 운영 시나리오
1. 대용량 알림 처리
// 대용량 알림 처리를 위한 샤딩 전략
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationShardingService {
private final List<NotificationChannelService> emailServices;
private final List<NotificationChannelService> smsServices;
public void sendBulkNotifications(List<NotificationRequest> requests) {
// 사용자 ID 기반 샤딩
Map<Integer, List<NotificationRequest>> shardedRequests =
requests.stream()
.collect(Collectors.groupingBy(
req -> Math.abs(req.getUserId().hashCode() % 4)));
shardedRequests.forEach((shardId, shardRequests) -> {
CompletableFuture.runAsync(() -> {
processShardRequests(shardId, shardRequests);
});
});
}
private void processShardRequests(int shardId, List<NotificationRequest> requests) {
log.info("Processing {} requests in shard {}", requests.size(), shardId);
for (NotificationRequest request : requests) {
try {
NotificationChannelService service = getServiceForShard(shardId, request.getChannelType());
service.sendNotification(request);
} catch (Exception e) {
log.error("Failed to send notification in shard {}: {}", shardId, request.getId(), e);
}
}
}
private NotificationChannelService getServiceForShard(int shardId, ChannelType channelType) {
switch (channelType) {
case EMAIL:
return emailServices.get(shardId % emailServices.size());
case SMS:
return smsServices.get(shardId % smsServices.size());
default:
throw new IllegalArgumentException("Unsupported channel type: " + channelType);
}
}
}2. A/B 테스트 지원
// A/B 테스트를 위한 알림 템플릿 관리
@Service
@RequiredArgsConstructor
@Slf4j
public class NotificationABTestService {
private final NotificationTemplateRepository templateRepository;
private final Random random = new Random();
public String selectTemplate(String baseTemplateCode, Long userId) {
// 사용자 ID 기반으로 A/B 테스트 그룹 결정
boolean isTestGroup = (userId % 100) < 50; // 50% 사용자를 테스트 그룹으로
if (isTestGroup) {
String testTemplateCode = baseTemplateCode + "_TEST";
boolean testTemplateExists = templateRepository.existsByTemplateCodeAndIsActiveTrue(testTemplateCode);
if (testTemplateExists) {
log.debug("Using test template for user {}: {}", userId, testTemplateCode);
return testTemplateCode;
}
}
log.debug("Using default template for user {}: {}", userId, baseTemplateCode);
return baseTemplateCode;
}
}알림 서비스 vs 기존 방식 비교
| 항목 | 기존 방식 (각 서비스에서 직접 발송) | 알림 서비스 방식 |
|---|---|---|
| 결합도 | 높음 (각 서비스가 알림 로직 포함) | 낮음 (이벤트 기반 분리) |
| 코드 중복 | 많음 (각 서비스마다 알림 코드) | 없음 (중앙 집중화) |
| 확장성 | 제한적 (각 서비스 개별 확장) | 높음 (독립적 확장) |
| 알림 통합 관리 | 어려움 | 쉬움 |
| 장애 격리 | 낮음 (알림 실패 시 메인 로직 영향) | 높음 (완전 분리) |
| 성능 | 동기 처리로 인한 지연 | 비동기 처리로 빠른 응답 |
| 모니터링 | 분산되어 어려움 | 중앙 집중 모니터링 |
| 템플릿 관리 | 코드 변경 필요 | 운영자 직접 수정 가능 |
결론
MSA 환경에서 알림 서비스는 시스템의 확장성, 안정성, 운영 효율성을 크게 향상시키는 핵심 컴포넌트입니다.
알림 서비스의 핵심 가치는 다음과 같습니다:
확장성: 각 서비스는 비즈니스 로직에만 집중하고, 알림 서비스는 독립적으로 확장하여 대용량 알림 처리가 가능합니다.
안정성: 메시지 큐를 통한 비동기 처리와 재시도 메커니즘으로 높은 안정성을 제공하며, 알림 실패가 메인 서비스에 영향을 주지 않습니다.
운영 효율성: 중앙 집중화된 템플릿 관리와 발송 이력 추적으로 운영 효율성을 대폭 향상시킵니다.
다만 메시지 큐 관리의 복잡성, 템플릿 관리 오버헤드, 초기 구현 복잡성 등을 고려해야 합니다.
실제 도입 시에는 서비스의 규모, 알림 발송량, 개발팀의 역량을 종합적으로 고려하여 단계적으로 적용하는 것이 중요합니다. 초기에는 핵심 알림부터 시작하여 점진적으로 확장하는 전략을 추천합니다.
728x90
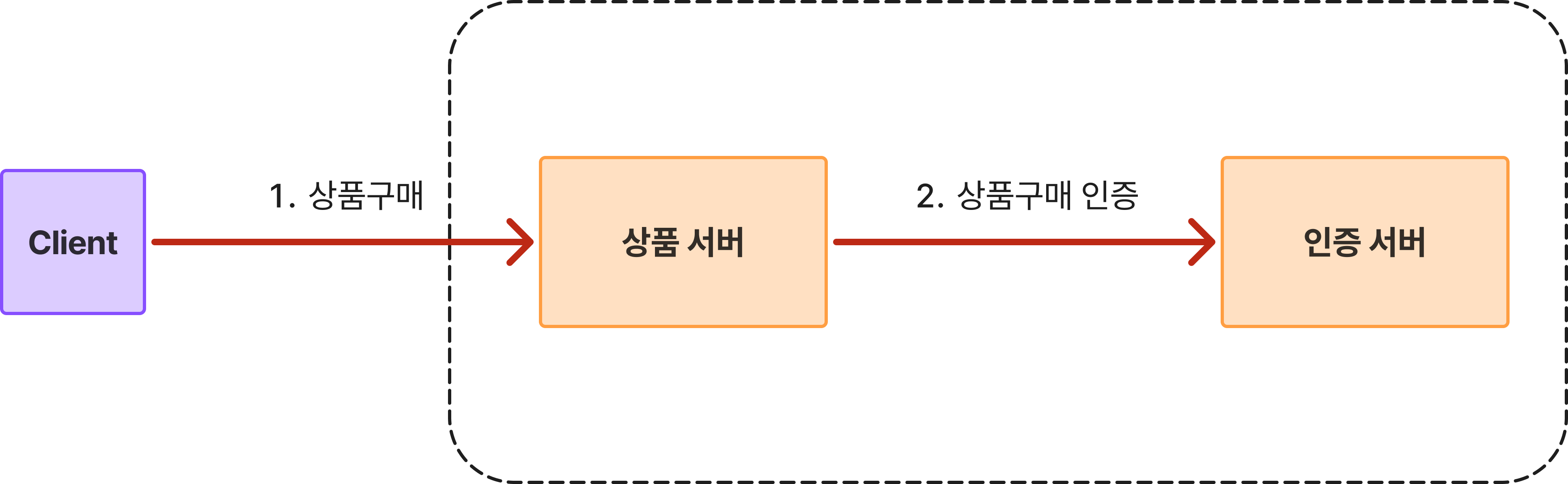
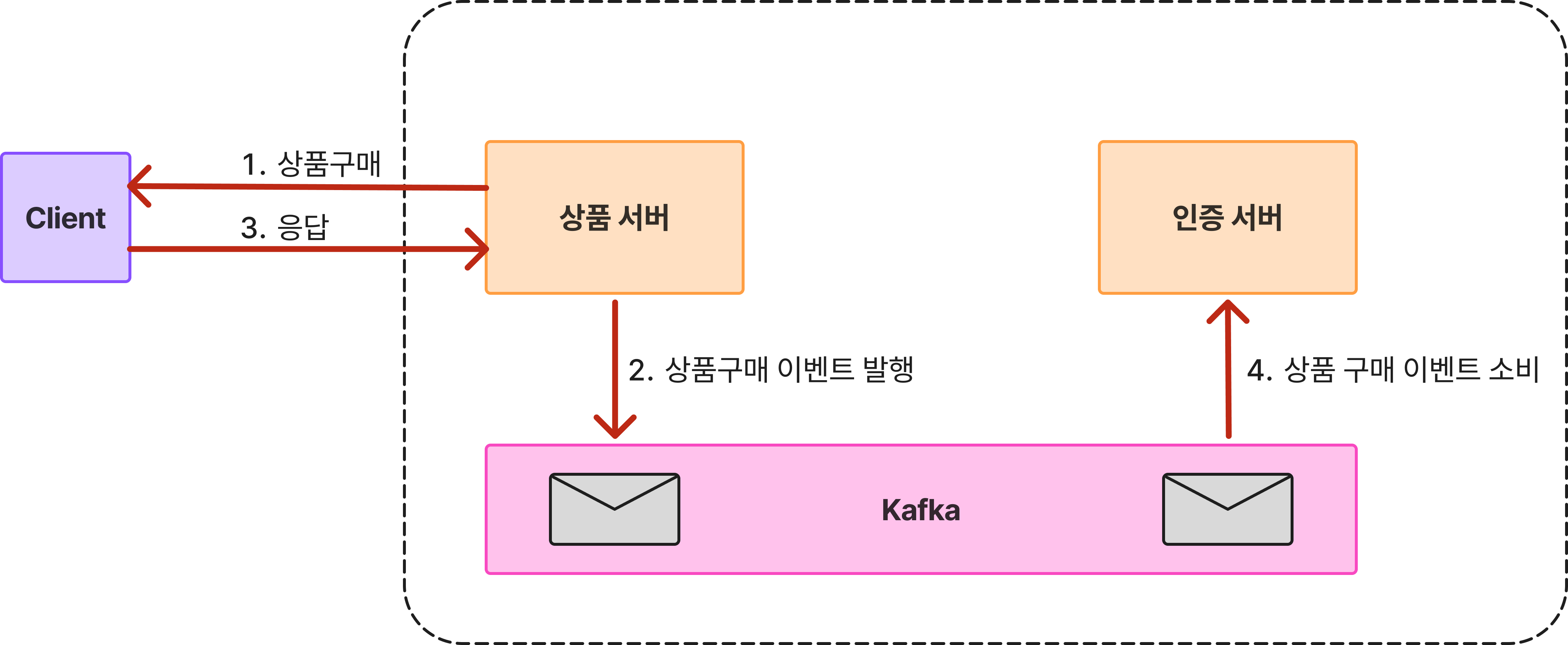
'Server' 카테고리의 다른 글
| 파티션과 샤딩에 관하여 (2) | 2025.06.30 |
|---|---|
| [Monorepo] 모노레포 그것이 답인가? (2) | 2025.05.22 |
| [해결 과제] 인증 서비스 왜 Refactoring 하였을까? (0) | 2025.04.04 |
| [EDA] EDA는 왜 적용하게 된걸까? (0) | 2025.04.03 |
| [MSA] 왜 MSA로 가야하나요? (0) | 2025.04.03 |