728x90

바보같이 너무 많이 생각해서 어려웠던 문제였습니다.
문제자체는 단순합니다.
parent 값들을 주고 해당 값으로 생성된 node들 중 하나를 삭제하고, 이후 leaf의 갯수를 알아내면 되는 문제입니다.
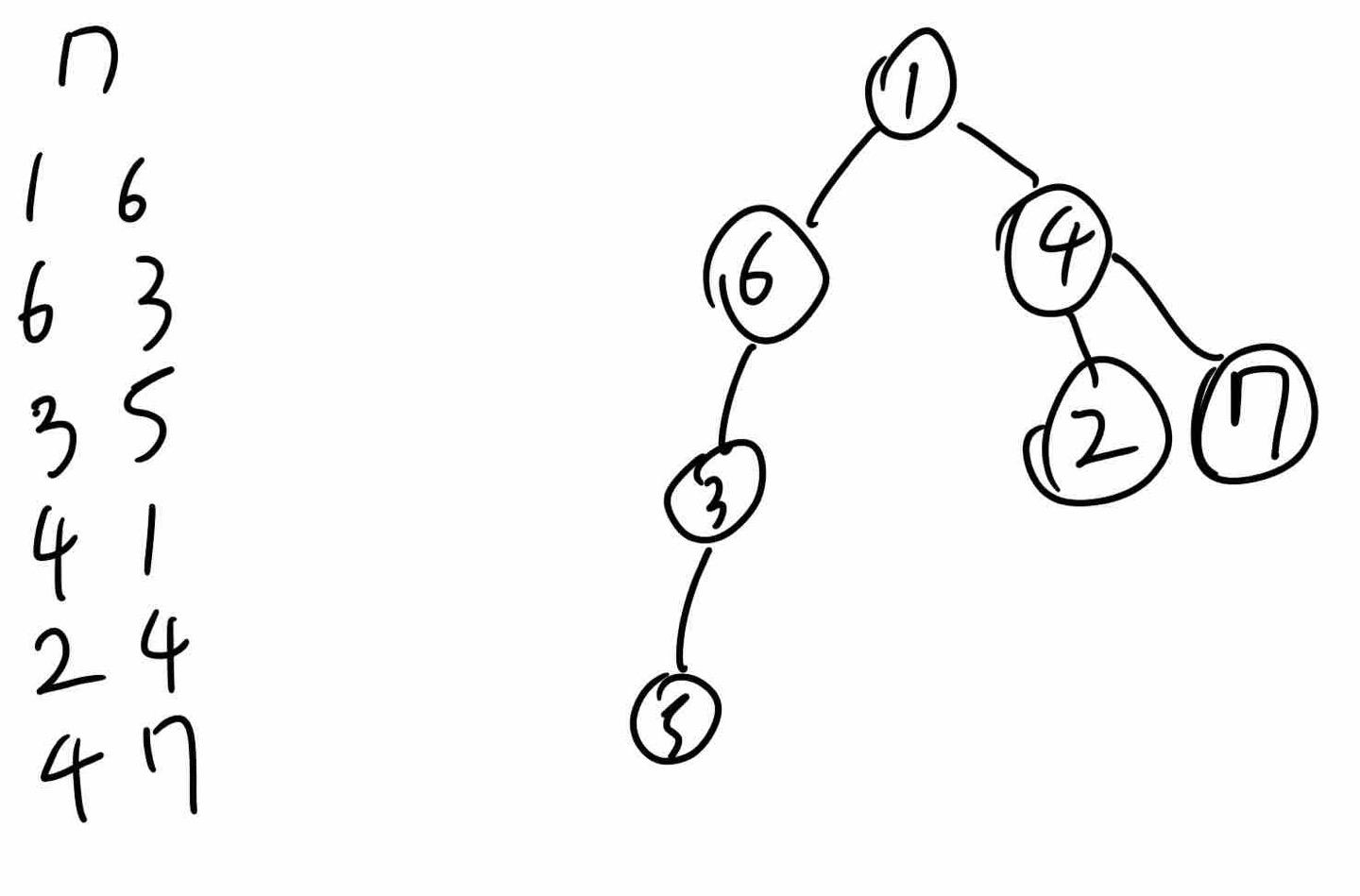
parent와 index값을 저장을 하고,
index를 부모로 가지는 node들을 child로 저장,
삭제된 노드들의 정보를 가지게 된다면 간단하게 해결할 수 있는 문제입니다.
다만 주의할 점은 현재 삭제된 노드들만 가지고 있는 노드 또한 leaf라는 점입니다.
이점은 코드를 확인해보며 찾아보시기 바랍니다.
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int N = Integer.parseInt(br.readLine());
int[] parents = new int[N];
boolean[] isDeleted = new boolean[N];
List<List<Integer>> graph = new ArrayList<>();
for(int i = 0; i <= N; i++) {
graph.add(new ArrayList<>());
}
int root = -1;
StringTokenizer st = new StringTokenizer(br.readLine());
for(int i = 0; i < N; i++) {
parents[i] = Integer.parseInt(st.nextToken());
if(parents[i] == -1) {
root = i;
} else {
graph.get(parents[i]).add(i);
}
}
int deleteNode = Integer.parseInt(br.readLine());
if(parents[deleteNode] > -1) {
delete(graph.get(parents[deleteNode]), isDeleted, deleteNode);
} else {
isDeleted[root] = true;
}
bw.write(countLeafNode(graph, isDeleted, root) + "");
bw.flush();
br.close();
bw.close();
}
public static void delete(List<Integer> graph, boolean[] isDeleted, int node) {
for(int child : graph) {
if(child == node) {
isDeleted[child] = true;
return;
}
}
}
public static int countLeafNode(List<List<Integer>> graph, boolean[] isDeleted, int node) {
if(isDeleted[node]) return 0;
if(graph.get(node).isEmpty()) return 1;
int count = 0;
for(int child : graph.get(node)) {
count += countLeafNode(graph, isDeleted, child);
}
return count == 0 ? 1 : count;
}
}728x90
'알고리즘 문제풀이' 카테고리의 다른 글
| [연습문제] 진료순서 정하기 코드 개선 (1) | 2025.02.15 |
|---|---|
| [ Tree ] 레드-블랙 트리 (0) | 2024.11.23 |
| [ 백준 - 9372 ]상준이의 여행 (2) | 2024.11.13 |
| [ 백준 - 11725 ] 트리의 부모 찾기 (0) | 2024.11.12 |
| [ 백준 - 29701 ] 모스 부호 (0) | 2024.11.11 |