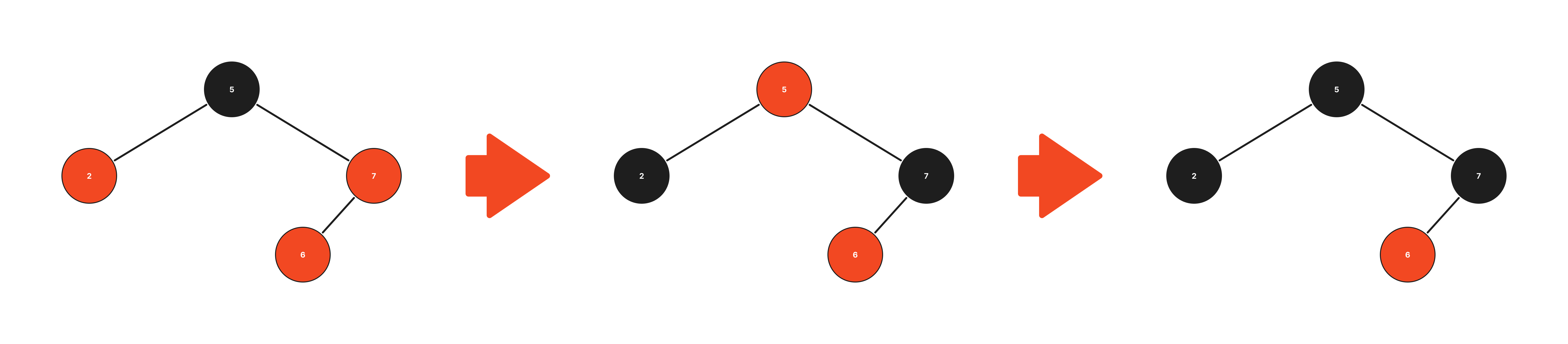
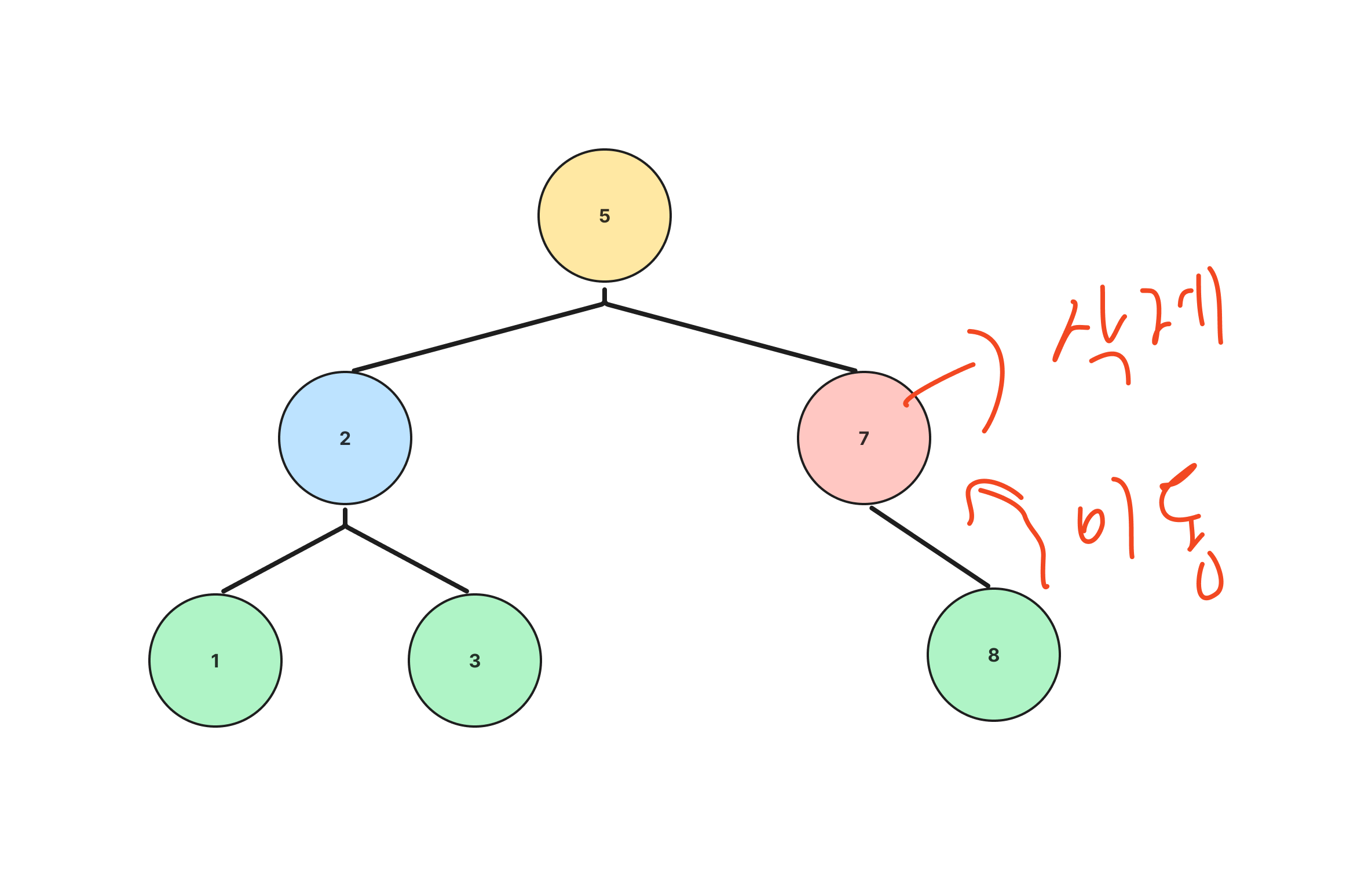
문제를 보면 모든 노드들은 연결이 되어있고, 모든 노드들을 돌아볼 때 가장 적은 종류의 비행기( 간선 정보 )를 타고 움직이는 수를 알아내야하는 것이 문제의 의도 입니다.
이때 우리는 모든 노드가 연결되어있고, 최소한의 경로로 모든 노드를 방문해야한다는 조건에서 최소신장 트리를 떠올릴 수 있어야 합니다.
최소신장 트리의 모든 노드를 연결하면서 가중치의 합을 구하면 되겠는데, 이때 값은 N - 1로써 가장 간단하게 구할 수 있습니다.
(N은 노드 수입니다.)
import java.io.*;
import java.util.*;
publicclassMain{
static BufferedReader br;
static BufferedWriter bw;
static StringTokenizer st;
publicstaticvoidmain(String[] args)throws IOException {
br = new BufferedReader(new InputStreamReader(System.in));
bw = new BufferedWriter(new OutputStreamWriter(System.out));
int T = Integer.parseInt(br.readLine());
StringBuilder sb = new StringBuilder();
while (T-- > 0) {
st = new StringTokenizer(br.readLine());
int n = Integer.parseInt(st.nextToken());
int m = Integer.parseInt(st.nextToken());
for (int i = 0; i < m; i++) {
br.readLine();
}
sb.append(n - 1).append("\n");
}
bw.write(sb.toString());
bw.flush();
br.close();
bw.close();
}
}
입력 예제를 확인해보면 N개의 노드와 N - 1개의 간선 정보가 주어지는 것을 확인해 볼 수 있습니다.
그림으로 표현하면 위와 같이 표현할 수 있으며, 해당 정보를 통해 2번부터 N번 까지 노드들의 부모정보를 출력하면 되는 문제입니다.
즉 2번의 부모 4, 3번의 부모 6, 4번의 부모 1, 5번의 부모 3, 6번의 부모 1, 7번의 부모 4번 해서 결과는 4, 6, 1, 3, 1, 4가 나오면 되는 것 입니다.
여기서 주의해야하는 점은 해당 트리는 자식 노드가 최대 2개가 주어진다는 말이 없으니 일반 트리이며, 자식 노드는 N개가 될 수 있다는 말입니다.
문제 풀이는 생각보다 간단합니다.
문제에서 트리의 루트를 1번으로 잡는다 하였으니, 1번의 자식들의 부모를 Bfs 탐색을 통해 확인한 다음 2번노드 부터 부모 번호를 출력해주면 됩니다.
publicclassMain{
publicstaticvoidmain(String[] args)throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
StringTokenizer st;
List<Integer>[] arr = new List[N + 1];
for( int i = 1; i <= N; i++ ) {
arr[i] = new ArrayList<>();
}
for (int i = 1; i < N; i++) {
st = new StringTokenizer(br.readLine());
int from = Integer.parseInt(st.nextToken());
int to = Integer.parseInt(st.nextToken());
arr[from].add(to);
arr[to].add(from);
}
int[] parent = newint[N + 1];
Queue<Integer> queue = new LinkedList<>();
queue.add(1);
parent[1] = 1;
while (!queue.isEmpty()) {
int current = queue.poll();
for(int child: arr[current]){
if (parent[child] == 0) {
parent[child] = current;
queue.add(child);
}
}
}
StringBuilder sb = new StringBuilder();
for (int i = 2; i <= N; i++) {
sb.append(parent[i]);
sb.append("\n");
}
System.out.println(sb);
}
}